
夜中の二時、予約投稿が時間どおりに出たかを確かめるために、管理画面のログを開いていました。布団に入る前の、最後のひと仕事のつもりでした。以前、予約メールが夜中だけ届かなかったことがあって、その不安がまだ体に残っていたからです。あのときの原因はWP-Cron がアクセスのないときに動かないことでした。深夜は誰もサイトに来ないので、cron も動かない。当たり前のことなのに、当時はそれに気づくまで何日もかかりました。今度は予約投稿を作る側になって、同じ相手ともう一度向き合うことになりました。
予約投稿というのは、一見すると単純な機能です。指定した時刻が来たら、記事を投稿する。それだけのはずでした。けれど作りはじめてすぐ、その「時刻が来たら」を誰が保証するのか、という問いにぶつかります。WordPress でその役目を負うのは WP-Cron ですが、これがまったく時間どおりに動いてくれない。早く動くこともあれば、何時間も遅れることもある。ひどいときは、同じ処理が立て続けに二回走る。予約投稿で二回走るというのは、同じ記事が二度投稿される、ということです。考えただけで肝が冷えました。
結論を先に置きます。WP-Cron を、正確な時計として信じるのをやめました。その代わりに、ズレても重複しても取りこぼしても、最終的に正しい状態へ収束する。そういう組み方に変えました。時計が狂っている前提で、それでも壊れない仕組みを下に敷く、という発想です。
WP-Cron は時計ではなく、ときどき来るキックだった
WordPress の予約実行を支える WP-Cron には、よく知られた性質があります。サイトにアクセスが来たときに、たまったタスクをまとめて処理する。だから、誰も来ない時間帯はタスクが動かず、アクセスが集中した瞬間に遅れていた分が一気に発火します。時刻ぴったりに動く保証は、最初からありません。
予約投稿プラグイン Rapls Relay を作りはじめたとき、この性質を「直す」方向では考えませんでした。WP-Cron の発火を正確にしようとしても、アクセス依存という根っこは変えられないからです。そこで発想を逆にしました。WP-Cron を時計だと思うのをやめて、「ときどき来るキック」として扱う。いつ来てもいい、二回来てもいい、しばらく来なくてもいい。来たときに、あるべき状態へ一歩進める。そういう前提で土台を組みました。
土台は三つの層でできています。状態を持つ自前のジョブテーブル。個々の配信アクションを並べるキュー(Action Scheduler)。そして、取りこぼしを拾う五分ごとの見回りです。順に書きます。
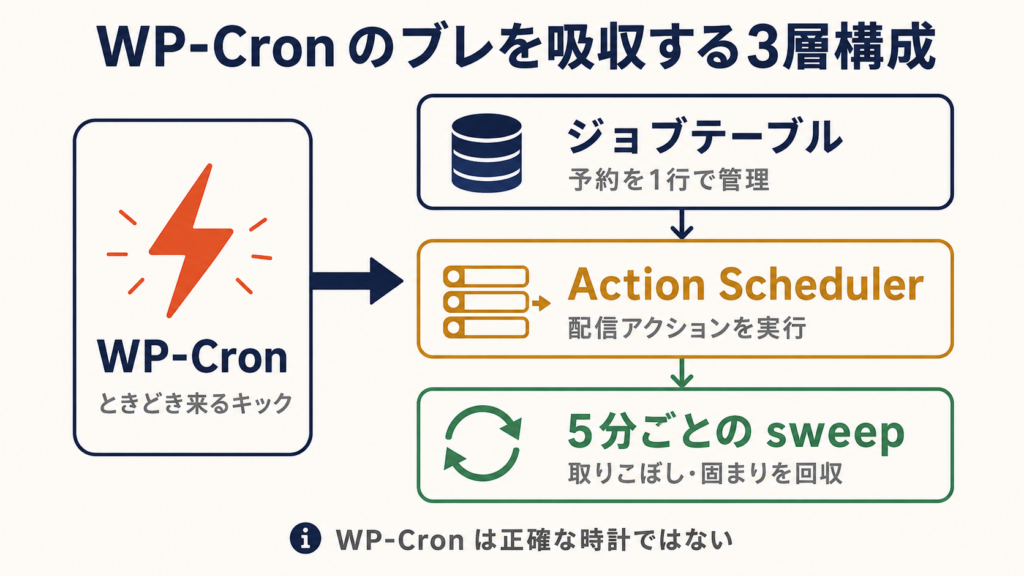
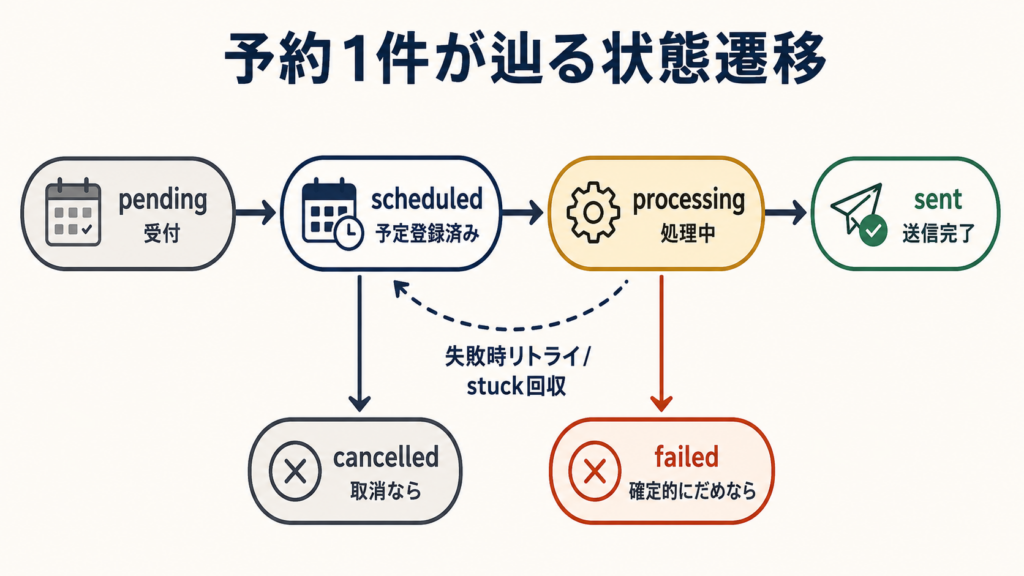
まず、ひとつの予約を一行のジョブとして持ち、状態を遷移させます。受付(pending)から、予定登録済み(scheduled)、処理中(processing)、送信完了(sent)へ。失敗すれば再投入され、確定的にだめなら failed で止まります。この一行が、いま各予約がどこにいるかの唯一の真実になります。Action Scheduler やログではなく、この自前テーブルを正にしたのが、あとで効いてきました。
なぜ自前のテーブルを持つのか、最初は迷いました。Action Scheduler にもタスクの状態は記録されるので、それを見ればいいのではないか、と。けれど Action Scheduler の状態は、あくまで「アクションを実行したかどうか」であって、「予約という業務がどこまで進んだか」ではありません。実行はしたが配信に失敗した、という状態を、自分の言葉で持っておきたかった。だから、予約の一生を表す状態は自分のテーブルに持ち、Action Scheduler は「実行のきっかけを並べる場所」と割り切りました。どちらが正なのかを曖昧にしておくと、障害が起きたときに「どっちを信じればいいのか」で必ず迷う。正を一つに決めておくことが、後々の自分を助けます。
二重投稿を、ロックではなく一行の更新で止めた
WP-Cron のいちばん厄介な性質が、さきほどの「たまった分をまとめて叩く」キャッチアップでした。これがあると、同じ配信アクションが二回発火しうる。SNS への予約投稿でこれが起きると、同じ内容が二度流れます。いちばん避けたい事故でした。フォロワーのタイムラインに同じ投稿が二つ並ぶのは、機能のバグというより、運用者の信用に関わる失敗です。一度やってしまうと、次から予約投稿そのものが怖くなる。
素直に考えると、ここで使いたくなるのはロックです。処理を始める前に鍵をかけて、終わったら開ける。けれど、ロックには嫌な弱点があります。鍵をかけたまま処理の途中で PHP が落ちると、鍵が開かないまま残る。すると、そのジョブは誰も触れなくなって、永遠に止まります。二重投稿を防ぐために入れた仕組みが、今度は「一度も投稿されない」という別の事故を生む。これでは本末転倒です。
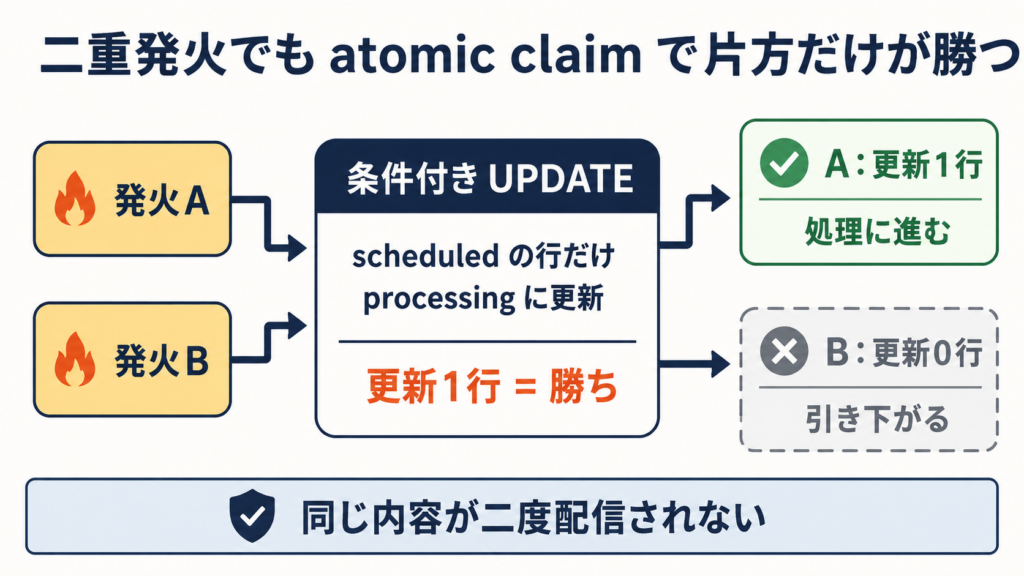
そこで、アプリケーション側のロックや DB の名前付きロックは使いませんでした。代わりに、条件付きの更新を一発だけ撃つという方法を取りました。ジョブの状態が「予定登録済み」のときだけ「処理中」に書き換える、という更新です。言葉にすると、こうなります。
- 状態が scheduled の行だけを processing に更新する
- 更新できた行数が 1 だった呼び出しだけが「勝ち」
- 更新が 0 行だった側は、すでに誰かが処理中にしたということなので、何もせず引き下がる
同じジョブが二回発火しても、先に更新できたほうだけが処理に進み、もう一方は空振りして即座に戻ります。データベースの行更新が一度に一つしか成立しない、その原子性だけを頼りに、二重配信を防いでいます。鍵をかけて開ける、という手続きが存在しないので、途中で PHP が落ちても、開きっぱなしの鍵は残りません。状態が processing で固まるだけで、それは後で見回りが拾います。つまり、最悪のケースでも「投稿されない」ではなく「少し遅れて投稿される」に落ちる。失敗の落としどころを、軽いほうへ寄せてあります。この「一行更新で勝者を一つに絞る」仕掛けが、設計のいちばんの肝です。
このとき、処理中にした時刻も一緒に記録しておきます。誰が、いつ、その行を取ったか。これが次の「固まり」の検出に効いてきます。
固まりと取りこぼしを、五分ごとの見回りで自己回復させる
キャッチアップを抑えても、まだ二つの穴が残ります。ひとつは、配信の処理中に PHP が落ちて、ジョブが「処理中」のまま固まること。もうひとつは、予定時刻が来ているのに、そもそも発火アクションが積まれていないこと。どちらも WP-Cron のブレが生む現象です。
これを、五分ごとの見回りで回収します。見回りも結局は WP-Cron のループに乗っているので完璧ではありませんが、定期的に状態を点検して、二種類のジョブを拾い直します。
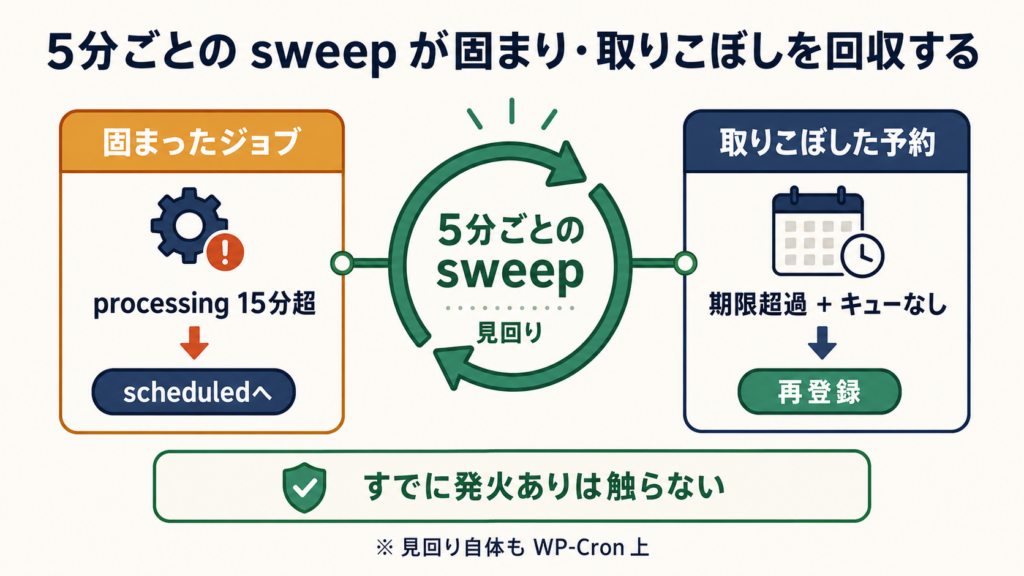
ひとつ目は、固まったジョブの回収です。処理中にしてから一定時間(十五分)を過ぎても処理中のままの行は、途中で落ちたとみなして、もう一度処理待ちに戻します。さきほど記録しておいた「処理中にした時刻」が、ここで判定材料になります。古すぎる処理中は、生きているのではなく死んでいる、と見る。
この十五分という数字には、少し迷いがありました。短くしすぎると、まだ生きて処理中のジョブを「落ちた」と誤判定して、二重に走らせてしまう。長くしすぎると、本当に落ちたジョブがいつまでも放置される。配信一回にかかる時間は、外部 API の応答待ちを含めても、ふつうは数十秒です。それが十五分も終わらないなら、まず間違いなく途中で死んでいる。生きている処理を巻き込まない余裕を取りつつ、死んだジョブを長く放置しない。その境目として十五分を置きました。ここは運用しながら調整する余地のある数字で、正解が一つに決まるものではありません。
ふたつ目は、取りこぼした予約の回収です。予定時刻を過ぎているのにまだ「予定登録済み」のままで、しかもキューに発火アクションも積まれていない行を探して、改めて登録し直します。ここで、すでに発火アクションが積まれている行には触れないようにガードを入れています。見回りが重なっても、同じ予約を二重に登録しないためです。回収の仕組み自体が、別の二重を生まないように作る。ここは慎重に組みました。
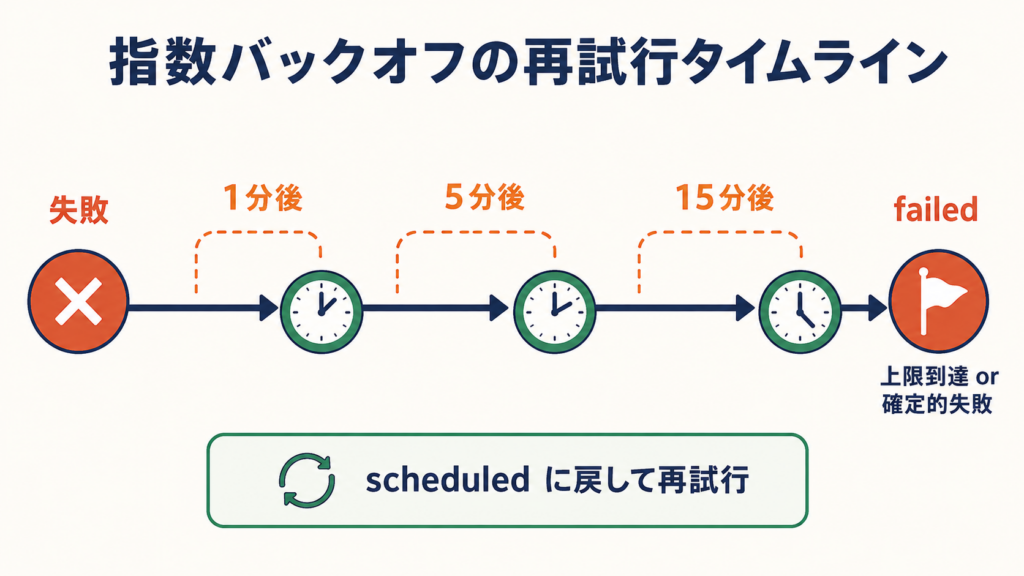
一時的な失敗は、捨てずに段階的に再試行します。一分後、五分後、十五分後と間隔を空けてリトライし、それでもだめなら、あるいは確定的にだめな種類の失敗なら、failed で止めます。再試行のときは、処理中の印を消して処理待ちに戻すので、さきほどの一行更新の仕組みがそのまま再利用されます。
間隔を一定にせず、だんだん広げているのには理由があります。失敗の多くは、相手側の一時的な不調です。API が混んでいる、ネットワークが一瞬切れた、レート制限に当たった。こういうとき、すぐに何度も叩き直すと、相手の負荷をさらに上げて、回復を遅らせることがあります。最初は短く、だめなら少し待ち、それでもだめならもっと待つ。相手に立ち直る時間を与えながら、こちらは諦めずに待つ。この「だんだん引く」やり方が、結果的にいちばん通りやすい。逆に、認証が通らないとか、リクエストの形式が間違っているといった、何度やっても結果が変わらない失敗は、リトライせずにすぐ failed にします。直らないものを待っても、時間を捨てるだけだからです。失敗を「待てば直るもの」と「待っても直らないもの」に分けて扱う。これが地味に効きます。
Action Scheduler が入っていない環境では、これらの仕組みは黙って壊れるのではなく、動かないことを管理画面で知らせる形にしました。静かに失敗するのがいちばん怖いからです。
それでも解けなかったこと
ここまでで、cron のキャッチアップによる二重投稿、配信中のクラッシュで処理が固まること、個別アクションの発火取りこぼし、一時的なネットワーク失敗、時刻のズレや遅延発火。これらは結果整合の設計で吸収できました。いつ発火しても、最終的には正しい状態へ収束します。

ただ、ひとつだけ、この設計でも救えない場合があります。サイトに誰も来ない、完全な無アクセス状態です。取りこぼしを拾う見回り自身も、結局は WP-Cron のループに乗っています。アクセスが来なければ、配信も見回りも、両方が止まる。土台を支えているものが止まれば、その上の安全網も一緒に止まる。これは構造上、プラグインの中だけでは解けません。
ここから先は、サーバー運用側の話になります。サーバーの実 cron で wp-cron.php を定期的に叩くか、Action Scheduler を WP-CLI のランナーで回すか。前作で予約メールを Xserver の cron に逃がしたのと、同じ結論にたどり着きました。アプリケーションでズレと重複と取りこぼしは吸収できる。けれど、cron がそもそも一度も回らないケースだけは、アプリケーションの外で担保するしかない。ここは正直に、サーバー cron 推奨にゆだねています。
振り返ると、今回やったことは、ぜんぶ同じ考え方の言い換えでした。土台が不確実なら、その上で正確さを取り戻そうとせず、不確実さを受け入れたうえで最終的に正しくなる仕組みを敷く。二重に発火するなら、勝者を一つに絞る。処理が固まるなら、古いものを死んだとみなして拾い直す。失敗するなら、待てば直るものだけ待つ。どれも「起きないようにする」のではなく「起きても大丈夫にする」方向です。起きないようにする設計は、起きたときに脆い。起きる前提の設計は、起きても崩れない。予約投稿という小さな機能を通して、そのことを手を動かしながら確かめていました。
ひとつ、この記事の前提も正直に書いておきます。状態の遷移、一行更新による勝者の確定、見回りによる回収。これらのロジック自体は、フレームワークに依存しないスモークテストで検証しました。ただ、実際のトークンを使った本番の配信(Qiita などへの実投稿)は、まだ検証できていません。設計とロジックは確かめた、本番配信はこれから。いま立っているのは、そこです。
検証環境:2026年6月16日 / WordPress 7.0 / PHP 8.3.30 / Rapls Relay 0.9.0(開発版)。
コメント