
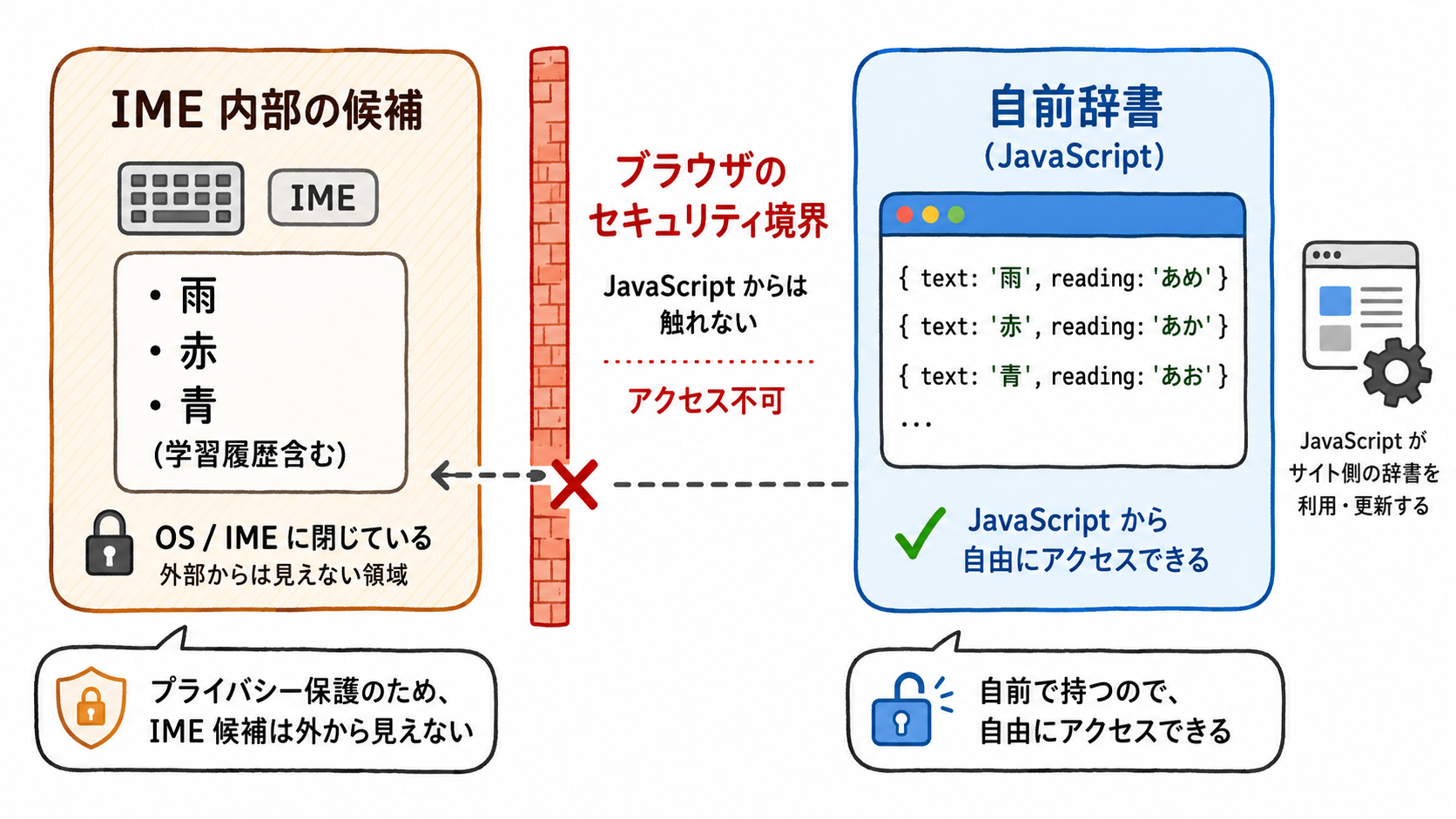
ブラウザの JavaScript から、IME の変換候補そのものを取得することはできません。「あ」と打って IME が内部に持っている「雨」「赤」「青」を、そのまま読めれば辞書を自作しなくていい。私はそう思って、最初の30分を、ありもしない API を探して溶かしました。先にこの結論を置きます。やることは逆で、IME の候補を取得するのではなく、自分で用意した辞書をサイト側で検索する。漢字と読みをセットにした辞書を持ち、その読みを前方一致で検索するだけです。この記事は、HTML と JavaScript だけで、その読み検索サジェストの土台を組み立てます。
完成イメージは、入力欄に「あ」と入れると、読みが「あ」から始まる候補がドロップダウンに並ぶ、という動きです。下の画面が、作りたかったものです。
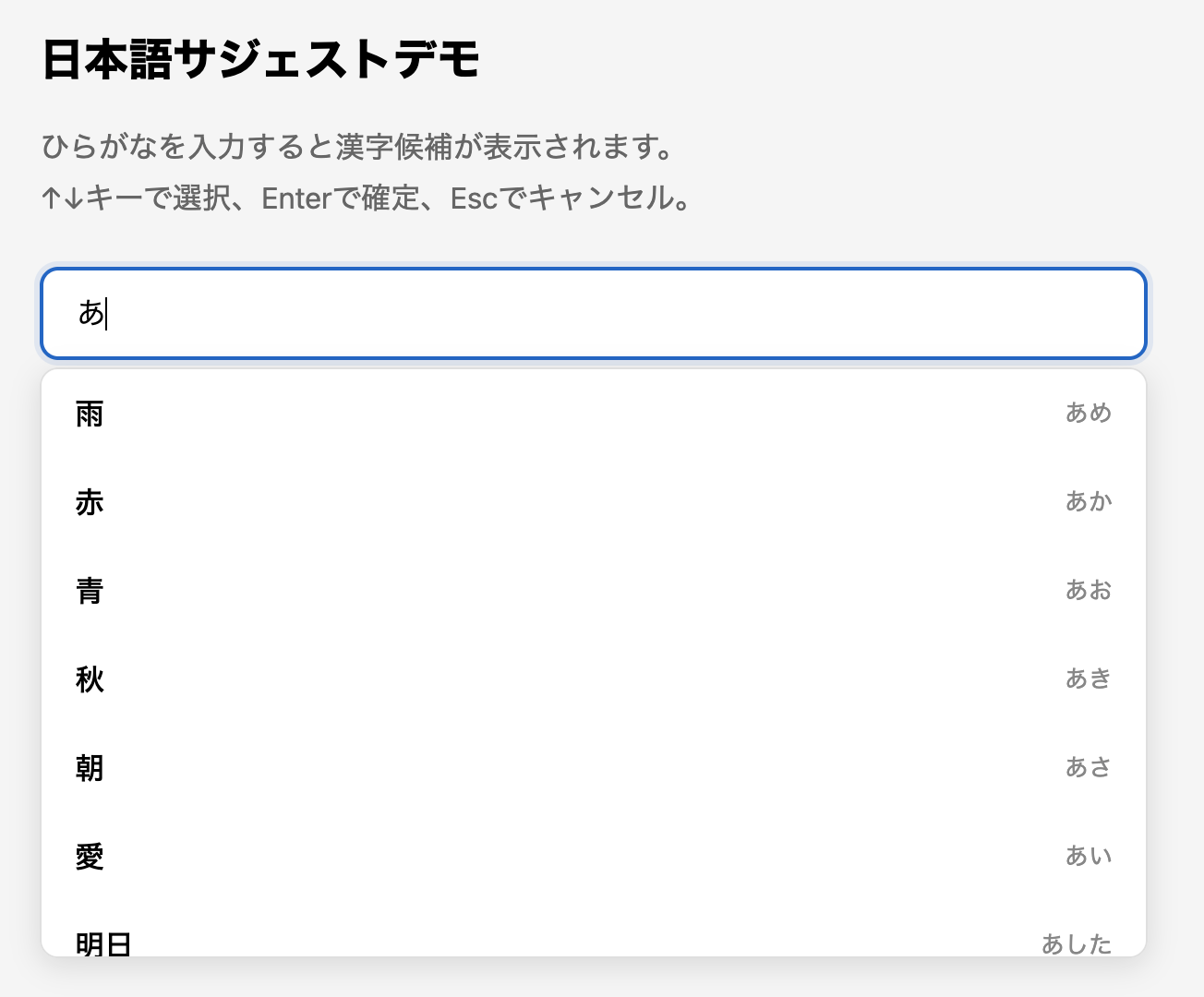
検証環境:Google Chrome 147 / macOS Tahoe 26.4 / JavaScript ES6+。検証は2026年4月、記事更新は2026年5月5日。この記事は基本編で、UI とキーボード操作は後編の実装版で扱います。
なぜ IME の候補は JavaScript から取れないのか
IME は OS 側で動く入力支援の仕組みです。JavaScript が扱えるのは、入力中の文字列と、合成が始まった・終わったといったイベント情報まで。候補そのものは壁の向こうにあります。これは不具合ではなく、守るための線引きです。IME には学習機能があり、過去に打った人名、住所、メールアドレスの一部が候補に出ることもある。それをサイトが自由に読めたら、確定前の入力まで覗けてしまうので、候補は触れない設計になっています。だから、取りに行くのをやめて、手元の辞書を検索します。
辞書はどう持てばいいのか
漢字や単語と、その読みをセットにした辞書を用意し、ユーザーが入れたひらがなで、読みが前方一致するものを探します。
| 1 2 3 4 5 6 7 | 辞書データの例: { text: "雨", reading: "あめ" } { text: "赤", reading: "あか" } { text: "青", reading: "あお" } 入力「あ」 → 読みが「あ」で始まる → 雨, 赤, 青 入力「あめ」 → 読みが「あめ」で始まる → 雨 |
ブログ内検索なら、記事タイトル、タグ名、カテゴリ名、よく検索される単語を辞書にしておくと便利です。小規模なサイトなら、JavaScript 内に辞書を持たせるだけで十分使えます。本格運用なら、WordPress 側で記事データから辞書を作って API で返す形にもできますが、仕組みを理解する段階では、ローカルの辞書がいちばんわかりやすいです。
日本語入力の「合成中」を、なぜ気にするのか
英語のサジェストなら input イベントを見るだけで動きます。日本語はそうはいきません。IME には合成という段階があるからです。ローマ字で a, m, e と打って「あめ」になり、Enter で確定するまで、入力は決まっていません。この合成中の文字列に毎回検索を走らせると、「あ」で出て、「あm」で消えて、「あめ」でまた出る、と候補がちらつきます。だから、合成中は検索せず、合成が終わったタイミングで検索します。
そのために、ブラウザには composition 系のイベントがあります。compositionstart は合成開始、compositionend は合成終了で発火します。下の図のとおり、サジェストで大事なのは最後の compositionend です。実装では isComposing というフラグで合成中かどうかを管理します。
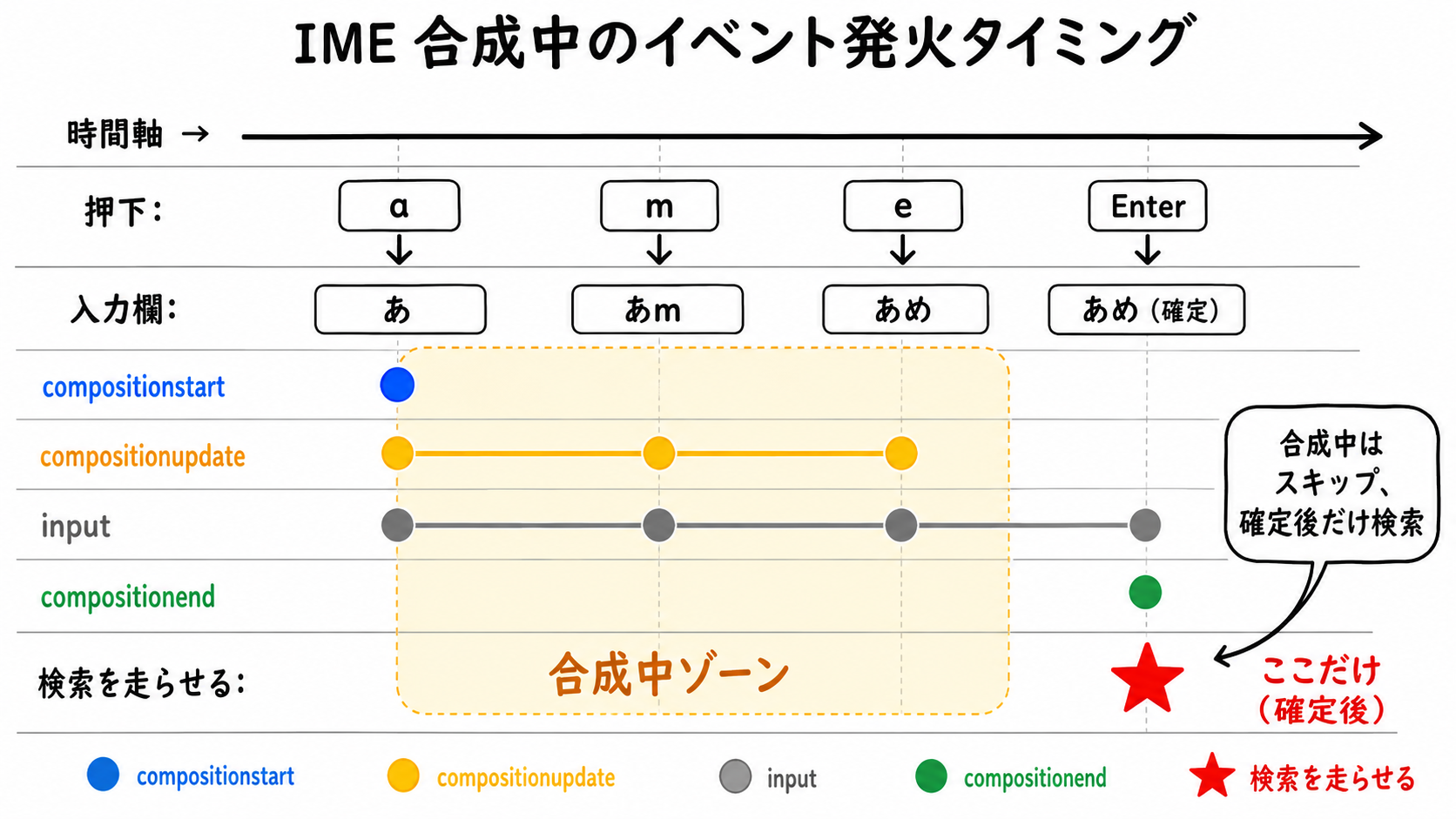
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | const input = document.getElementById('searchInput'); let isComposing = false; input.addEventListener('compositionstart', () => { isComposing = true; }); input.addEventListener('compositionend', () => { isComposing = false; performSearch(input.value); }); input.addEventListener('input', (e) => { if (e.isComposing || isComposing) return; // 合成中はスキップ performSearch(e.target.value); }); |
input イベントにも isComposing プロパティはありますが、環境によって挙動に差が出ることがあります。だから e.isComposing だけに頼らず、自前のフラグも併用します。ここを雑にすると、コードは動くのに使いにくいサジェストになります。
検索は何回走らせるのか
合成中の検索を止めたら、次は回数です。候補が細かく更新されすぎると画面が落ち着かず、将来 API 経由にするなら入力のたびにリクエストが飛ぶのも避けたい。そこで debounce を使います。最後の入力から少し待って、それ以上続かなければ1回だけ実行する仕組みです。setTimeout で予約し、次の入力が来たら clearTimeout で前の予約を取り消すだけ。ローカル辞書なら 100〜200ms でも体感はほぼ即時で、外部 API なら 300ms 前後にするなど、通信回数とのバランスで決めます。
候補をそのまま innerHTML に入れていいのか
だめです。候補を画面に出すときは HTML エスケープを忘れないようにします。今回の辞書は自分で用意するので危険な文字列は入りにくいですが、ユーザー投稿、外部 API、WordPress の記事タイトルを候補に使うなら話が変わります。候補文字列をそのまま innerHTML に入れると、意図しない HTML や JavaScript が走る危険があります。textContent に入れてから取り出すと、< や & が安全な文字列に変換されます。サンプルでは省かれがちですが、実際のサイトに組み込むなら最初から入れておくほうが安心です。
ここまでで使った部品を並べると
辞書、合成中の判定、debounce、読み検索、HTML エスケープ。ここまでを1つにすると、こうなります。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | const dictionary = [ { text: '雨', reading: 'あめ' }, { text: '赤', reading: 'あか' }, { text: 'アメリカ', reading: 'あめりか' }, { text: '天気予報', reading: 'てんきよほう' }, // サイトに合わせて追加 ]; function debounce(func, delay) { let timeoutId = null; return function (...args) { if (timeoutId !== null) clearTimeout(timeoutId); timeoutId = setTimeout(() => func.apply(this, args), delay); }; } function escapeHtml(text) { const div = document.createElement('div'); div.textContent = text; return div.innerHTML; } function searchByReading(query) { const q = query.toLowerCase().trim(); if (!q) return []; let results = dictionary.filter(item => item.reading.startsWith(q) || item.text.toLowerCase().startsWith(q) ); results.sort((a, b) => { const aExact = a.reading === q || a.text.toLowerCase() === q; const bExact = b.reading === q || b.text.toLowerCase() === q; if (aExact && !bExact) return -1; if (!aExact && bExact) return 1; return a.reading.length - b.reading.length; }); return results.slice(0, 10); // 候補は多すぎると選びにくい } const input = document.getElementById('searchInput'); let isComposing = false; input.addEventListener('compositionstart', () => { isComposing = true; }); input.addEventListener('compositionend', () => { isComposing = false; updateSuggestions(input.value); }); function updateSuggestions(query) { const results = searchByReading(query.trim()); console.log('検索結果:', results); // 次のステップで、ここに候補表示UIを追加する } const debouncedUpdate = debounce(updateSuggestions, 150); input.addEventListener('input', (e) => { if (e.isComposing || isComposing) return; debouncedUpdate(e.target.value); }); |
読み検索では、reading だけでなく text 自体も対象にしておくと、「あめりか」でも「アメリカ」でも候補に出せます。ソートは完全一致を優先し、「あめ」なら「雨」を上に、「あめりか」をその後に出します。この段階では結果を console.log に出すだけです。いきなり UI を作り込むより、入力に対して正しい候補が返るかを先に確認するほうが、切り分けが楽になります。
WordPress やブログ内検索に応用するには
サンプルでは辞書を JavaScript 内に直接書いています。実際のサイトでは、候補データをどう作るかが効きます。記事タイトルは読みたい記事への最短の導線に、カテゴリ名やタグ名はまとめ読みの入口に、よく検索されるキーワードは需要の高い候補として、自作プラグイン名や商品名は固有名のタイプミスを救う候補として使えます。小規模なサイトなら、候補データを JSON で出力してブラウザ側で検索しても、数十件から数百件なら体感速度は十分です。候補が多い場合や検索ログで候補を変えたい場合は、サーバー側で検索して結果だけ返す設計が向きます。まずは小さな辞書で動かして、サイトに合うかを確かめる。これがいちばん遠回りしない順番でした。
次の自分に渡すメモ
最初の30分、私は OS や IME に閉じている処理を、ブラウザ側で覗こうとしていました。当然そんな API はなく、探した時間はそのまま消えた。流れが変わったのは、取得をやめて自前の辞書を検索する、と切り替えた瞬間です。そこからは、読み検索も、合成中の判定も、debounce も、エスケープも、迷わず書けました。JavaScript で日本語を扱うときは、OS や IME に閉じている処理を、ブラウザ側に持ち込もうとしていないかを最初に確認すると、無駄な調査が減ります。詰まったら、コードを疑う前に、前提を取り違えていないかを一度疑う。あの30分が教えてくれたのは、それでした。ここまでで候補を探す頭脳はできたので、画面に出してキーボードで選べるようにする UI は、後編で実装します。
関連記事
- 日本語サジェストの実装版|キーボード操作・blur 競合・WAI-ARIA・API 連携まで直して、ようやく使える検索 UI にした話。本記事の続編で、候補リストのキーボード操作と blur 競合への対処、API 連携までを扱います。
- 姓名フォームのフリガナ自動入力を composition イベントで自前実装した話。同じ composition イベントを使った別実装です。
- 日本語フォームの半角カナ・全角英数を input と blur で使い分けて自動変換する話。日本語フォーム実装シリーズの仕上げです。


コメント