
日本語フォームに混入する半角カナや全角英数を、JavaScript で自動変換したい。そう思ったとき、まず手が伸びるのは input イベントだと思います。私もそうでした。ところが実際に検証用の HTML を組んで実測してみると、input ハンドラは、想像していたのとはまったく違う場面でしか動きませんでした。その「違う場面」が、この記事の核になっています。
姓名フォームのフリガナ自動入力をはじめとした日本語フォーム実装シリーズの4本目、シリーズの仕上げに位置する記事です。シリーズの前3本は、「あ」→「雨」を自力で実装する|IME に頼らない日本語サジェストの作り方、日本語サジェストの実装版|キーボード操作と blur 競合まで直して、ようやく使える検索 UI にした話、姓名フォームのフリガナ自動入力を composition イベントで自前実装した話 の3本です。あわせて読んでいただくと、日本語入力まわりの全体像が見えやすいかもしれません。
クライアント側で半角カナや全角英数を自動変換する話に絞っています。サーバー側の正規化(WordPress でいうと mb_convert_kana() 一発)については深く触れません。
検証環境: macOS Tahoe 26.4 / Google Chrome 148 / ATOK 35。Safari、Firefox、Edge、Windows + MS-IME、Google 日本語入力、iOS、Android などは未確認です。
数年前、半角カナの送信ログを見た日
もう何年か前、受託で作った web フォームの送信ログを眺めていたら、一部のレコードに半角カナが混じっていました。「ヤマダ タロウ」のような表記です。当時はサーバー側の PHP で mb_convert_kana() を通すだけで片付けてしまいました。1行で済む処理ですし、それで実害もなかったので、深く考えずにそのままになっていたんですよね。ただ、いま振り返ると、ユーザーが入力している最中にクライアント側で変換していれば、もう少し気の利いた UX になったはずです。サーバーで正規化しても、画面には半角カナのまま残っていて、ユーザーには「なんでこの形で受け取ってるんだろう」と感じさせていたかもしれません。そこで今回、シリーズの仕上げとして、この半角カナ・全角英数の自動変換をクライアント側で実装してみることにしました。検証用の HTML を組んで実測してみたら、想像していたのとは違う場面でしか入力中ハンドラが動かない、という発見があり、それが本記事の核になっています。
混入経路を、ひとつずつ
「半角カナを入力する人ってそんなにいるんですか?」と聞かれたことがあります。たしかに、自分から進んで半角カナを打つ人は少ないと思います。ただ、混入する経路は意外と多いんです。
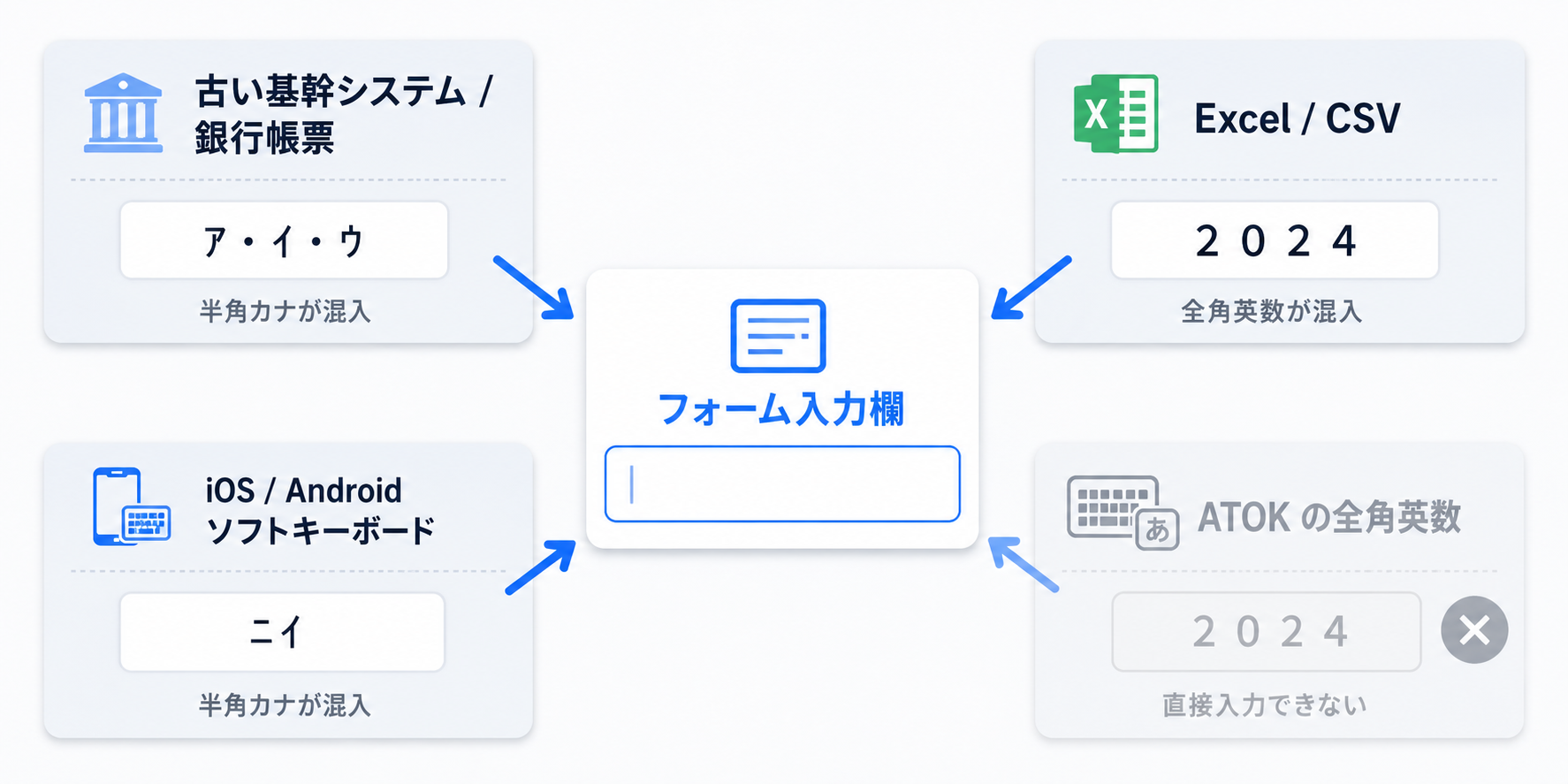
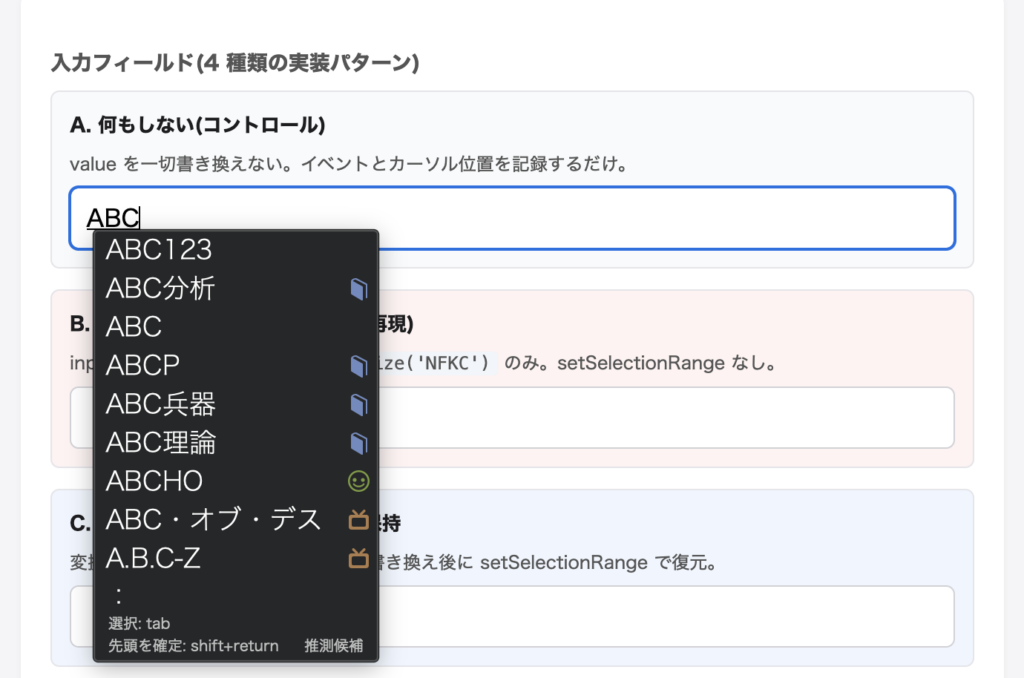
まず多いのが、コピペです。銀行系の古い帳票や基幹システムだと、いまだに半角カナが標準で使われている場面があります。そこから値をコピーしてフォームに貼り付ければ、そのまま半角カナで入ってしまう。Excel や CSV からのコピペでも、全角英数が混入することがあります。Excel のセルで「2024」と打ったつもりが、状況によって全角の「2024」になっていて、コピペで気づかずフォームに入る、というパターンです。iOS や Android のソフトウェアキーボードも、機種や設定によってはカタカナを半角で出すことがあります。ユーザー本人は「カタカナで打った」としか思っていないので、半角になっていることに気づきません。残るのは、IME で意図的に出すパターン。これも経路としてはあるはずだ、と思って実際に検証してみたら、想像と違っていました。ATOK 35 + Chrome 148 で、全角英数の「ABC」を出そうとしてみると、ATOK は最初から半角の「ABC」で文字を返してきたんです。
|
1 2 |
compositionupdate data="A" input data="A" isComposing=true value="A" |
compositionupdate.data が、最初から半角の「A」になっています。ATOK で全角英数を入力するには、いったん半角で打ったあとに「全角に変換」というワンアクションが必要です。普通に打って自然に出てくる文字ではない、ということが分かりました。つまり、半角カナや全角英数が混入する経路の主役は、ユーザーが IME で意図的に出すケースではなく、コピペや別アプリからの値の流入だったわけです。先に言ってしまうと、この事実が、記事後半の実装判断をほぼ決めることになります。
クライアントか、サーバーか、の前に
正規化をクライアントとサーバー、どっちでやるかは最初に決めておく必要があります。どちらにも一長一短があるので、「どっちか一方だけ」よりも「両方で重ねる」のが現実的だと感じています。サーバー側のいいところは、確実なところです。クライアントの JavaScript はユーザーが無効化することもできますし、bot からのリクエストでは動きません。サーバーで mb_convert_kana() を通しておけば、データベースに入る値は必ず正規化されたものになります。クライアント側のいいところは、UX が良いこと。ユーザーが打った値が、その場で「正しい形」に変わる様子が見えますし、送信前にユーザー自身で変換結果を確認できるのも大きな利点です。多層防御という言葉ほど大層な話ではないんですが、クライアントで第一段階の変換をして UX を担保し、サーバーで念のためもう一度正規化する。保険を二重にかけておく、くらいの感覚です。

この記事ではクライアント側の実装に絞って書いていきます。サーバー側の話はほぼ mb_convert_kana() 一発で終わってしまうので、書くことが少ないんですよね。
変換タイミング、4つの置きどころ
クライアント側で半角カナや全角英数を変換する場合、「いつ」変換処理を走らせるかに、いくつかの選択肢があります。それぞれ役割が違うので、表で整理してみます。
| タイミング | イベント | 主な役割(実測ベース) |
|---|---|---|
| 入力中 | input |
コピペ対策。IME 経由の入力には触れない |
| IME 確定直後 | compositionend |
IME 経由の値を最終確定時に拾う |
| フォーカス離脱時 | blur |
コピペ・IME 経由・あらゆる経路の最終チェック |
| 送信時のみ | submit |
確実だがユーザーが結果を確認できない |
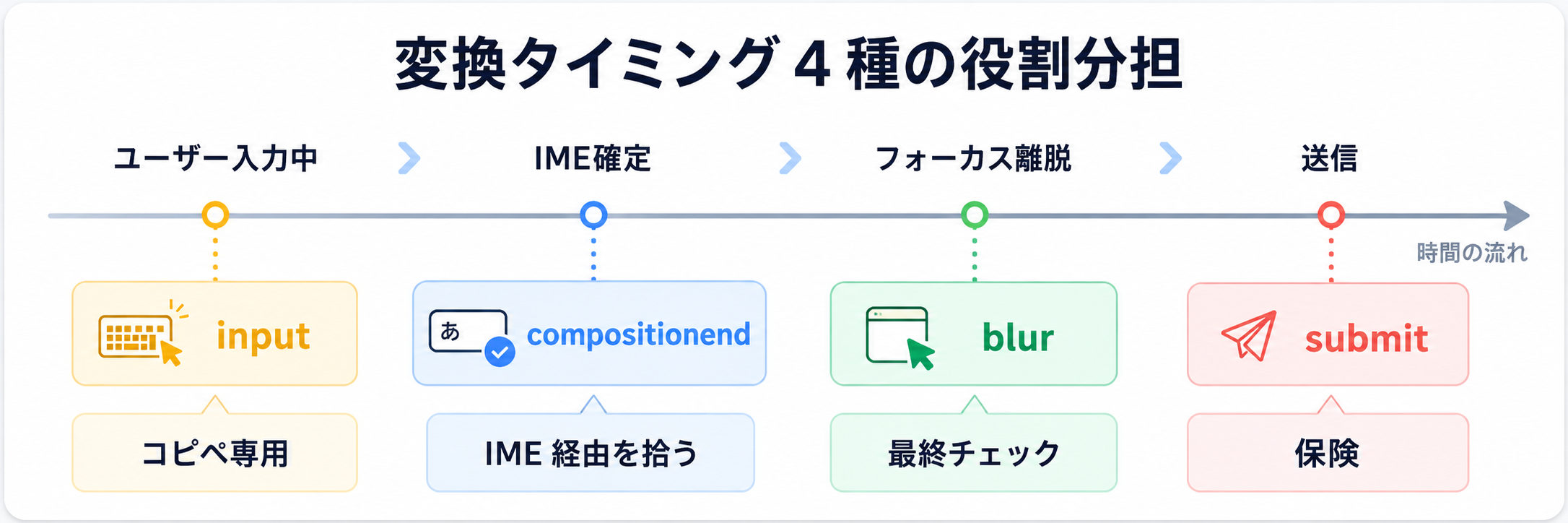
input イベントで変換するのは、見た目には一番派手です。「ヤマダ」と打った瞬間に「ヤマダ」に変わる動きは、ユーザーに「ちゃんと反応してる」という安心感を与えます。ただ、後で実測した結果から分かるんですが、IME 経由の入力ではそもそもこのハンドラに到達しません。compositionend は、姓名フォームのフリガナ自動入力の記事でも使ったイベントです。日本語入力との整合性が高くて、IME が動いている最中に value を書き換えないので安全。ただし、半角カナのコピペは IME を経由しないので、このタイミングだけだと拾えない場面があります。blur は、フォーカスが他のフィールドへ移ったときに変換が走ります。コピペでも IME 経由でも、最終的に必ず通るので、保険としては一番強力。一方、フィールドを離れた瞬間に値が書き換わるので、「あれ、自分が打ったやつと違う」と感じるユーザーがいるかもしれません。submit 時の一括変換は、確実なんですが、ユーザーが変換後の値を確認できません。確認画面のあるフォームならいいんですが、そうでないと「自分が打った内容」と「DB に入った値」がずれることになります。結局、今回の実装では input と blur の組み合わせを基本にしました。コピペは input で即座に拾い、IME 経由を含めた最終チェックは blur に任せる。役割分担です。
実測してみたら、input は素通りした
検証用の HTML を組んで、4種類の実装パターンでログを取ってみました。フィールド A は何もしないコントロール、B は単純に value を書き換える、C は setSelectionRange でカーソル位置を保持、D は blur のときだけ変換、という構成です。
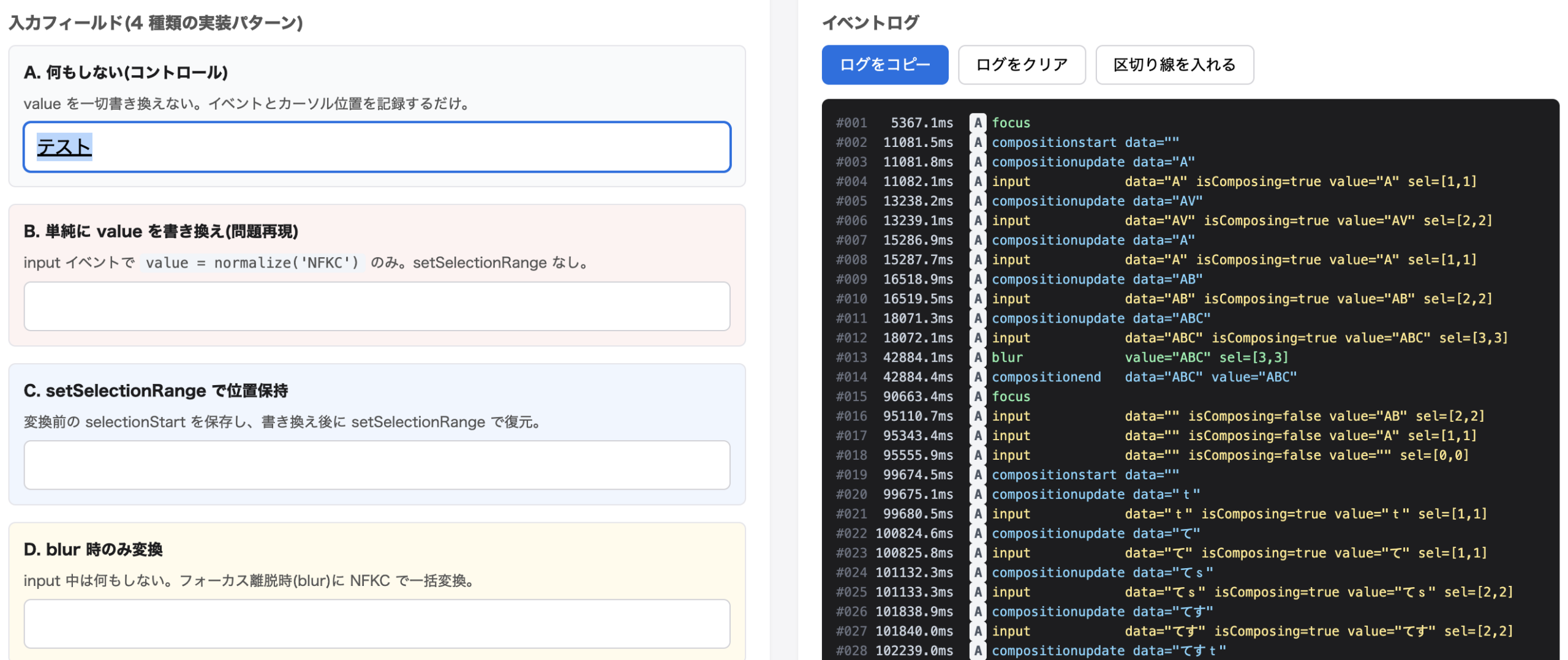
最初に試したかったのは、よく語られる「input イベント内で value を書き換えるとカーソルが末尾に飛ぶ」現象の再現でした。ところが、ATOK で「あいうえお」を打って半角カナの「アイウエオ」に変換しても、フィールド B の書き換えハンドラが一度も発火しないんです。
|
1 2 3 4 5 6 |
#031 16653.6ms Bcompositionupdate data="アイウエオ" #032 16654.2ms Binput data="アイウエオ" isComposing=true value="アイウエオ" sel=[0,5] #033 17962.5ms Bcompositionupdate data="アイウエオ" #034 17963.4ms Binput data="アイウエオ" isComposing=true value="アイウエオ" sel=[5,5] #035 17963.5ms Bcompositionend data="アイウエオ" value="アイウエオ" #036 19282.8ms Bblur value="アイウエオ" sel=[5,5] |
表示される input イベントは、すべて isComposing=true です。フィールド B のハンドラは先頭で if (e.isComposing) return; としているので、IME 経由の入力では一度も本体に到達しません。compositionend で IME が確定したあとに input が追加で発火することもなく、value はそのままです。ここで少し振り返るのですが、姓名フォームのフリガナ実装で compositionend を扱っていたときの感覚で、つい「入力中ハンドラ」と呼んでいたんですが、実際には IME 経由の入力にはまったく関わっていなかったんですね。

では、入力中ハンドラはいつ動くのか。コピペで試してみました。別アプリから「アイウ」をコピーして、フィールド B に貼り付けたときのログがこれです。
|
1 2 3 |
#006 28180.9ms Bpaste pastedText="アイウ" #007 28181.5ms Binput data="アイウ" isComposing=false value="アイウ" sel=[3,3] #008 28181.7ms B⚙ value rewrite value: "アイウ"(len=3) → "アイウ"(len=3, ±0) | cursor: 3 → 3 |
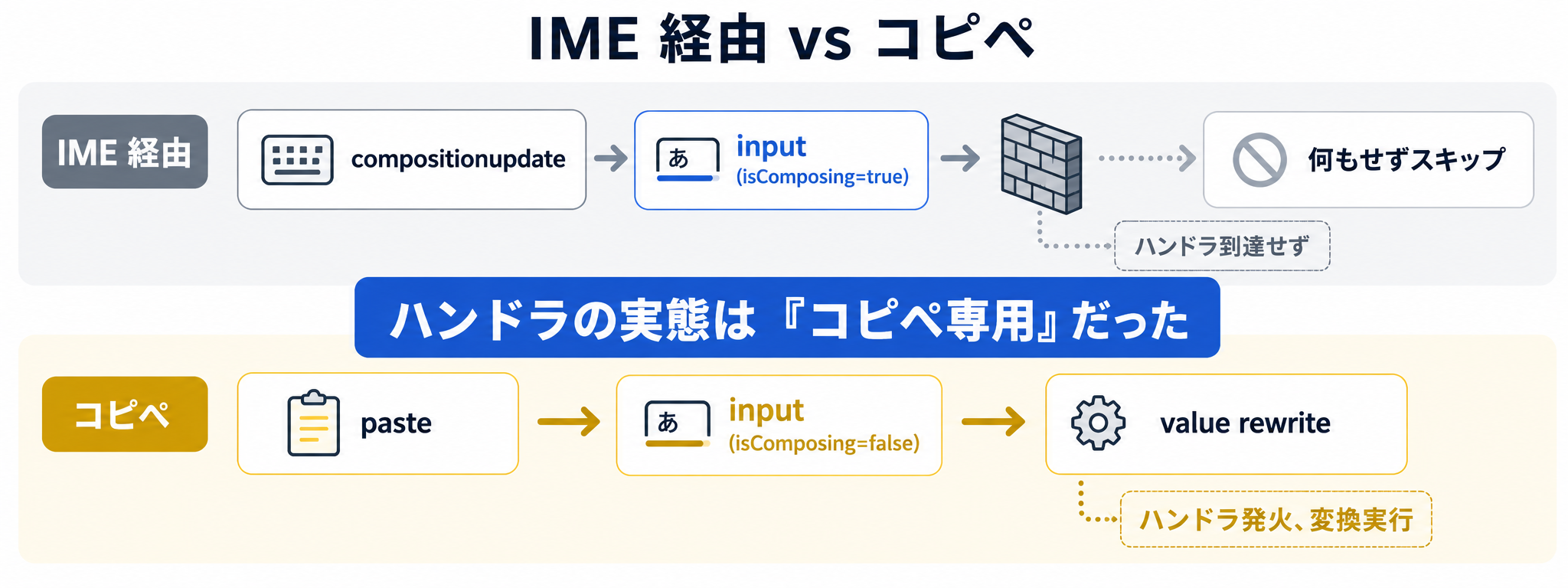
isComposing=false で input が発火して、書き換えハンドラまで一気に動いています。コピペした瞬間に半角カナが全角カナに置き換わって、カーソル位置もそのまま。ここで腑に落ちました。入力中の input ハンドラの本当の用途は、IME 経由の入力対応ではなく、コピペで流入した値の即時変換だったということです。事前に予想していた挙動と、まったく違っていました。「カーソル位置が末尾に飛ぶ」という、よく語られる現象を再現したくて検証用 HTML を組んだはずなんですが、ATOK + Chrome の組み合わせだと、再現する場面が思っていたよりずっと限定的でした。コピペは文字数が変わらないことが多いので、ハンドラ内で setSelectionRange を呼ばなくてもカーソルは維持されます。setSelectionRange を呼ぶフィールド C と、呼ばないフィールド B の挙動に、コピペでは差が出ませんでした。
これは ATOK 35 + Chrome 148 での結果です。Windows + MS-IME や Google 日本語入力では、IME 経由でも isComposing=false の input が追加で発火する可能性があります。古いブラウザや別の入力環境では、再現する場面があるかもしれません。
あえて言うなら、入力中ハンドラを書く意味があるかは、混入経路の現実を見て判断するのがよさそうです。コピペが主な経路で、ユーザーが手で半角カナを打つ場面がほぼないなら、入力中ハンドラは「コピペ対策の最初の砦」として機能します。逆に、IME 経由で半角カナを打たれる頻度が高い環境だと、入力中ハンドラは効かないので、blur での最終チェックが必須になります。
NFKC、便利さの裏の落とし穴
JavaScript には String.prototype.normalize() という便利なメソッドがあります。'NFKC' を渡すと、Compatibility Composition と呼ばれる正規化が走ります。
|
1 2 3 |
'ヤマダ'.normalize('NFKC'); // → "ヤマダ" '2024'.normalize('NFKC'); // → "2024" 'Abc'.normalize('NFKC'); // → "Abc" |
半角カナを全角カナに、全角英数を半角英数に、両方とも1行で変換できます。短いし、自前で変換テーブルを書くより安全に思えますよね。ただ、これに乗っかると、知らないうちに地雷を踏むことがあります。NFKC は「互換等価」と呼ばれる文字も展開してしまうので。
|
1 2 3 4 5 |
'①'.normalize('NFKC'); // → "1" '㈱'.normalize('NFKC'); // → "(株)" '㌔'.normalize('NFKC'); // → "キロ" '⁉'.normalize('NFKC'); // → "!?" '㎏'.normalize('NFKC'); // → "kg" |

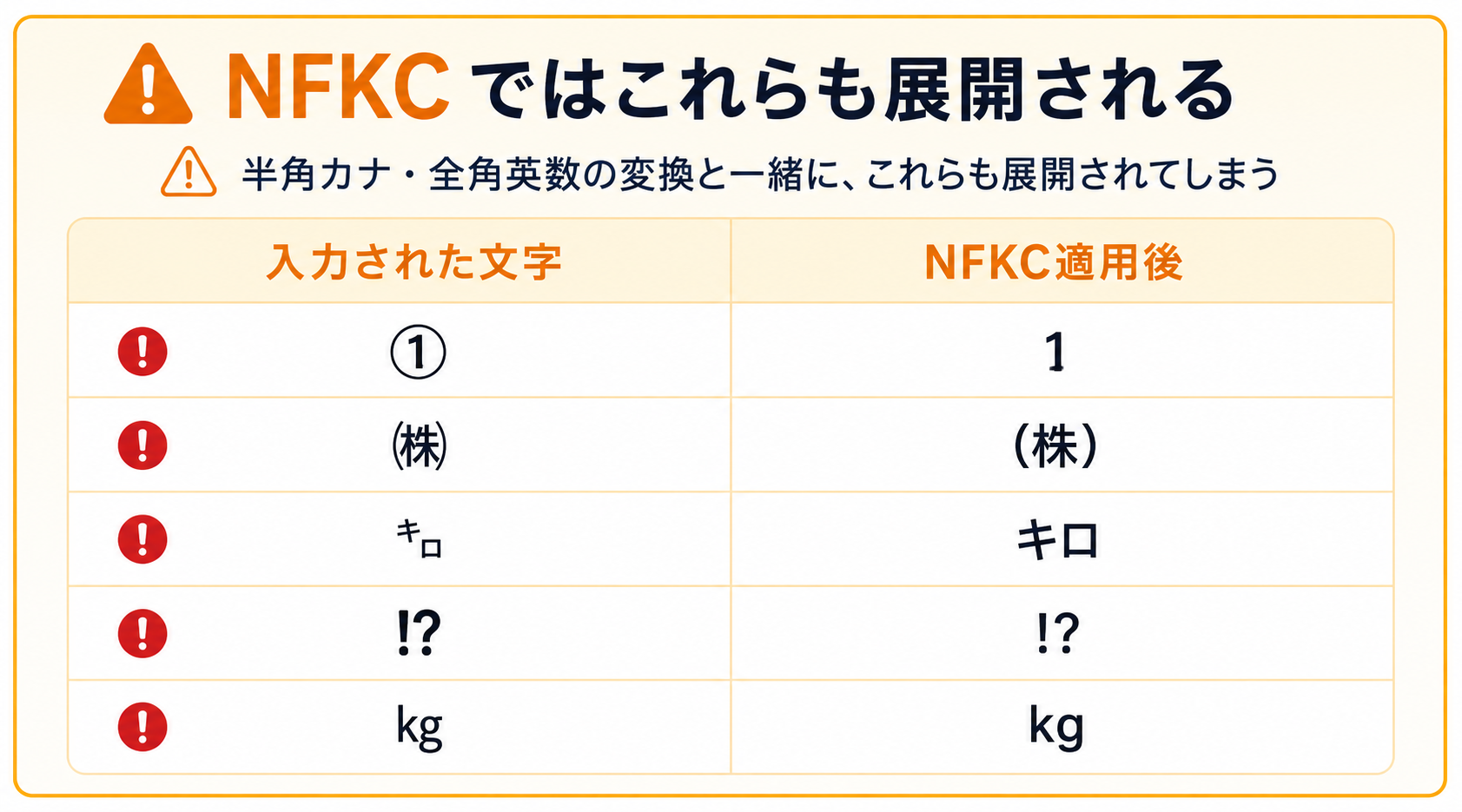
丸付き数字、株式会社の合字、単位記号、感嘆符の合字。これらが全部分解されます。フォームによっては、これが致命的になることがあります。検証用 HTML のフィールド D で「①対応希望」と入力して、blur で変換を走らせてみました。
|
1 2 |
#144 34330.3ms Dblur value="①対応希望" sel=[5,5] #145 34331.6ms D⚙ value rewrite value: "①対応希望"(len=5) → "1対応希望"(len=5, ±0) | cursor: 5 → 5 |
ユーザーが入力した「①対応希望」が、フォーカスを離した瞬間に「1対応希望」になります。文字数は同じですが、ユーザーから見たら「自分が打った文字と違う」と感じるはずです。姓名や電話番号、郵便番号みたいに、入力できる文字種があらかじめ絞られているフィールドなら、NFKC で広く正規化しても問題は起きにくいです。一方で、自由記述や住所のフィールドだと、丸付き数字を使う人がいるので、NFKC を一律にかけるのはリスクがあります。対処の仕方としては、フィールドごとに NFKC を使うかどうかを決めるのが一番現実的です。今回の実装でも、姓名やカナのような文字種限定フィールドにだけ NFKC を当てて、自由記述には触らない方針にしています。もう一段こだわるなら、自前の変換テーブルを書く手もあります。半角カナと全角カナの対応表、全角英数と半角英数の対応表だけを持って、それ以外の文字は触らない。コードは長くなりますが、副作用は確実に避けられます。手間と安全性のトレードオフです。
blur 時のカーソルの動き
blur で変換が走るときも、カーソル位置の挙動を見ておきました。フォーカスが外れた直後なので UX には影響しないんですが、挙動として知っておくと、別の場面で似た問題に出くわしたとき助かります。文字数が変わらない変換、たとえば「アイウンエオ」(半角カナ6文字)を「アイウンエオ」(全角カナ6文字)に変換するときのログです。
|
1 2 |
#094 43842.1ms Dblur value="アイウンエオ" sel=[4,4] #095 43843.7ms D⚙ value rewrite value: "アイウンエオ"(len=6) → "アイウンエオ"(len=6, ±0) | cursor: 4 → 6 |
文字数は同じなのに、カーソル位置が 4 から 6(末尾)にずれています。value への代入の瞬間に、ブラウザがカーソルを末尾にリセットしているんですね。もう一段おもしろいのは、文字数が変わる変換のときです。「ガギ」(半角カナ + 半角濁点で4文字)を「ガギ」(全角カナで2文字)に変換するとどうなるか。
|
1 2 |
#082 24016.1ms Dblur value="ガギ" sel=[4,4] #083 24016.7ms D⚙ value rewrite value: "ガギ"(len=4) → "ガギ"(len=2, -2) | cursor: 4 → 2 |

文字数が 4 から 2 に減っています。カーソルはもともと 4(末尾)でしたが、変換後の文字列の長さが 2 になったので、ブラウザが自動的に 2 にクランプしました。位置 4 はもう存在しないので、有効な範囲に収まるよう調整されたわけです。この挙動は blur 後なのでユーザーは気づきません。ただ、もし input イベント中に文字数が変わる変換を走らせたら、ユーザーから見てカーソルが思わぬ位置に飛ぶ場面が出てきそうです。今回の実装で入力中変換でこの問題を踏むのは、半角濁点付きカナをコピペしたときに限られます。事前に動作確認しておけば実用上は問題ないレベルかなと思っています。
カタカナとひらがな、0x60 の距離
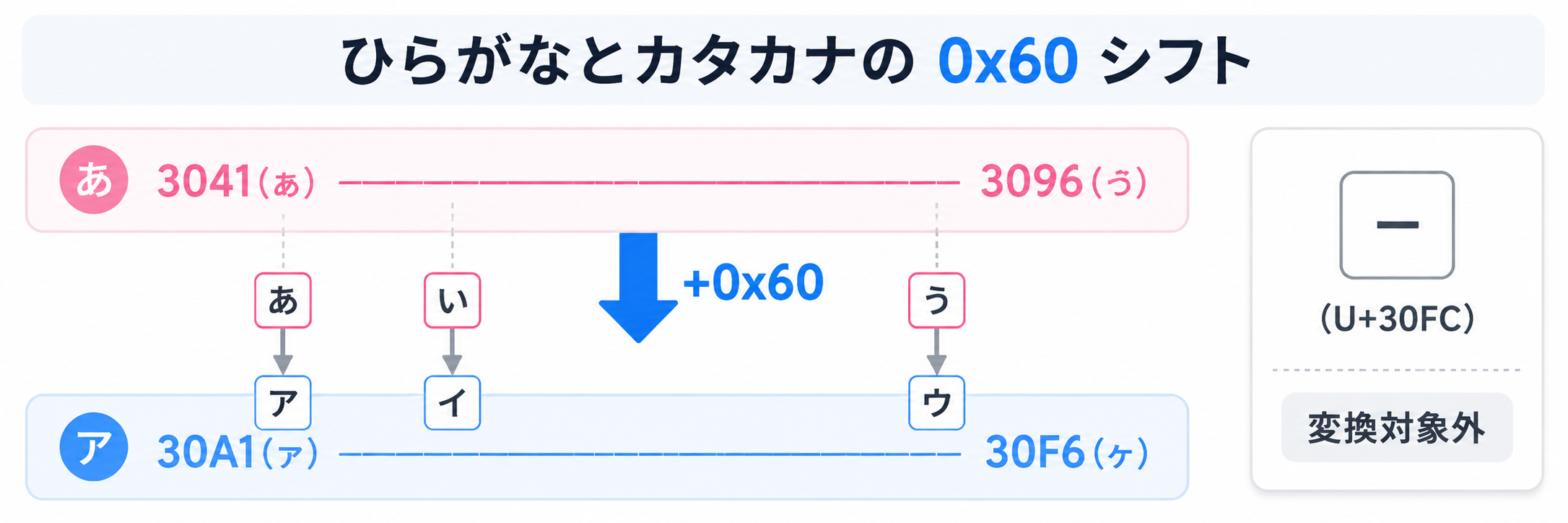
姓名フォームのフリガナ欄で「全角カタカナのみ受け付ける」という仕様にしたい場面があります。ユーザーがひらがなで入れたら自動でカタカナにする、というやつです。カタカナとひらがなは、Unicode 上で 0x60(96)離れた位置にきれいに並んでいます。「あ」(U+3042)の 0x60 後ろに「ア」(U+30A2)がある、という具合に。だから、コードポイントを足し引きするだけで変換できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// ひらがな → カタカナ function hiraganaToKatakana(str) { return str.replace(/[\u3041-\u3096]/g, (ch) => { return String.fromCharCode(ch.charCodeAt(0) + 0x60); }); } // カタカナ → ひらがな function katakanaToHiragana(str) { return str.replace(/[\u30A1-\u30F6]/g, (ch) => { return String.fromCharCode(ch.charCodeAt(0) - 0x60); }); } |
気をつけたいのが、長音記号「ー」(U+30FC)。これがひらがなのレンジにもカタカナのレンジにも入っていないんです。長音記号はカタカナ語でもひらがな語でも共通で使うので、変換対象から外しておけば問題ありません。「ヴ」(U+30F4)については、対応するひらがな「ゔ」(U+3094)があります。範囲指定 [\u30A1-\u30F6] には「ヴ」も含まれるので、-0x60 で「ゔ」に変換されます。これは何も気にしなくて大丈夫。このカタカナ⇄ひらがな変換と、半角カナ→全角カナ変換、全角英数→半角英数変換を組み合わせると、フリガナフィールドで「全角カタカナのみ」を強制できます。
|
1 2 3 4 5 6 7 |
function normalizeKana(str) { // 半角カナ → 全角カナ、全角英数 → 半角英数 let normalized = str.normalize('NFKC'); // ひらがな → カタカナ normalized = hiraganaToKatakana(normalized); return normalized; } |
これを blur や input で呼べば、ユーザーが「やまだ」「ヤマダ」のどちらを入れても、最終的に「ヤマダ」になります。「Yamada」みたいなローマ字入力は別の話なので、英字入力をバリデーションで弾くか、ローマ字→カタカナの変換を別途仕込むかになります。
WordPress のフォームプラグインでは
WordPress でフォームを作るときは、Contact Form 7、WPForms、Gravity Forms あたりのプラグインを使うことが多いと思います。どれを使っていても、JavaScript を読み込む口さえ用意できれば、本記事のロジックはそのまま流用できます。Contact Form 7 だと、フォームのテンプレートで各フィールドにクラス名を指定できます(class:js-normalize-kana のように)。テーマの functions.php で wp_enqueue_script を使って読み込んだ JavaScript から、document.querySelectorAll('.js-normalize-kana') で対象フィールドが取れます。WPForms の有料版にはカスタム JavaScript を書くブロックがあって、Gravity Forms は gform_post_render フィルターでフォームレンダー後に JavaScript を実行できます。注意したいのは、これらのプラグインの一部機能(条件付きフィールド、複数ステップフォームなど)を使っているとき。フィールドの DOM が動的に追加されるパターンだと、最初に querySelectorAll で取った時点では追加分が拾えません。MutationObserver でフィールドの追加を監視して、新しく追加されたフィールドにイベントリスナーを後付けする処理が必要になります。
完成形のコードと、リリース前のチェック
ここまでの判断を全部入れた最小実装です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
<form> <label> フリガナ <input type="text" id="kana" class="js-normalize-kana"> </label> </form> <script> function hiraganaToKatakana(str) { return str.replace(/[\u3041-\u3096]/g, (ch) => { return String.fromCharCode(ch.charCodeAt(0) + 0x60); }); } function normalizeKana(str) { let normalized = str.normalize('NFKC'); normalized = hiraganaToKatakana(normalized); return normalized; } document.querySelectorAll('.js-normalize-kana').forEach((input) => { // コピペ対策(input イベントは isComposing=false のときのみ動く) input.addEventListener('input', (e) => { if (e.isComposing) return; const cursorPos = e.target.selectionStart; const original = e.target.value; const normalized = normalizeKana(original); if (normalized !== original) { e.target.value = normalized; e.target.setSelectionRange(cursorPos, cursorPos); } }); // 最終チェック(IME 経由を含むすべての経路の保険) input.addEventListener('blur', (e) => { e.target.value = normalizeKana(e.target.value); }); }); // 送信時の最終チェック document.querySelector('form').addEventListener('submit', (e) => { document.querySelectorAll('.js-normalize-kana').forEach((input) => { input.value = normalizeKana(input.value); }); }); </script> |
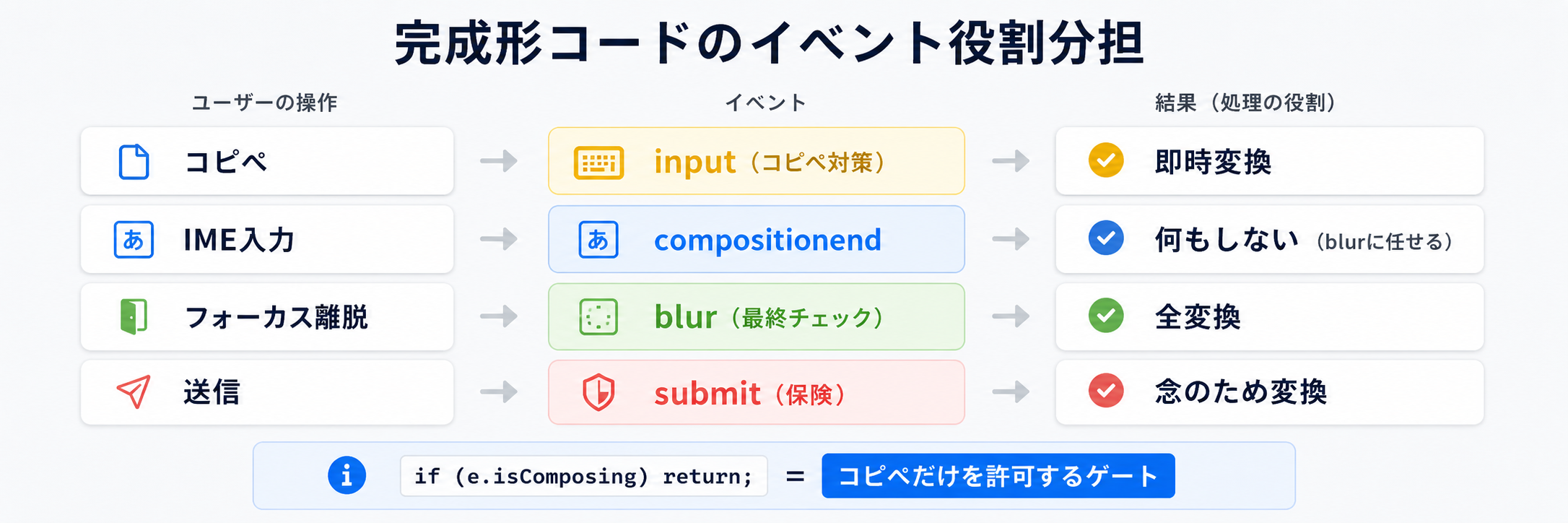
input ハンドラの先頭に if (e.isComposing) return; を入れています。これは前章の実測で確認したように、IME 経由の入力では isComposing=true の input しか発火しないので、このチェックがあっても IME 中の動作には影響がありません。むしろ、コピペで isComposing=false の input が来たときだけ反応するという、本来の役割を果たすための仕組みになっています。setSelectionRange は、文字数が変わる変換(半角濁点付きカナのコピペなど)に備えての保険です。文字数が同じならカーソルは末尾に飛ぶだけなので影響は限定的ですが、念のため入れています。blur は最終チェックです。IME 経由・コピペ経由・どの経路でも、最後に必ず通ります。フォーカスが外れた瞬間に動くので、ユーザーが「自動で値が変わった」と感じる場面はありますが、フリガナフィールドのように「全角カタカナで揃っているはず」という前提があるところでは、これくらい強めでちょうどいいかなと思います。submit は最後の保険です。JavaScript が一部無効化されたり、想定外のフローで送信されたりするケースのため。サーバー側の正規化と二重に走りますが、害はありません。
実装したフォームをリリースする前のチェックリストです。
- 「ヤマダ タロウ」と半角カナで入力(または IME 変換)→ blur で全角カナに変換されるか
- 「アイウ」を別アプリからコピペ → input ハンドラの即時変換で全角カナになるか
- 「2024」と全角数字を入力 → 半角に変換されるか
- 「ABC」と全角英字を入力 → 半角に変換されるか
- 「やまだ」とひらがなで入力 → カタカナに変換されるか(フリガナ欄の場合)
- 「①」を入力 → 自由記述フィールドでは「1」に変換されないか確認
- IME で変換中(Space キーで候補表示中)に値が勝手に書き換わらないか
- フォームを送信したとき、最終的に正規化された値が送られるか
- iPhone Safari、Android Chrome でも動くか
とくに最後のモバイル確認は、ソフトウェアキーボードの挙動が PC と違うことが多いので、必ず実機で見ておくことをおすすめします。
シリーズ4本を通して
これで、日本語フォーム実装シリーズの4本が揃いました。前3本は IME 入力の途中経過を扱った記事でしたが、本記事は IME を経由しない混入経路にスポットを当てています。
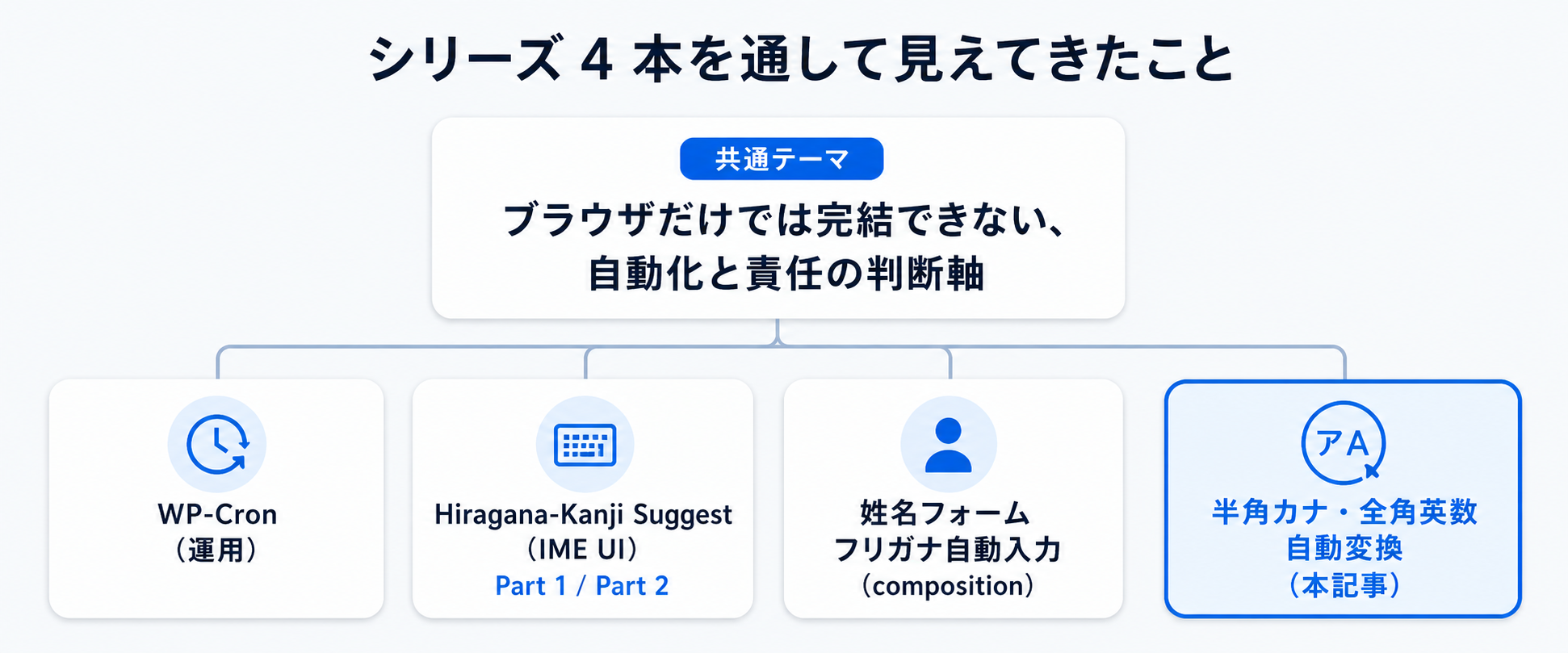
シリーズを通して何度も出てきたのは、「ブラウザだけでは完結できないので、入力規則をどこまで自動化して、どこからユーザーの責任にするか」という判断の話でした。フリガナ欄を編集可能のままにしておくのも、自由記述では NFKC をかけないのも、根は同じ判断だと思います。完璧な自動化を目指すと、必ずどこかで副作用が出ます。そして、検証してログを取ると、事前に予想していた挙動と違う場面が必ず出てきました。姓名フォームのフリガナ実装では、ATOK の推測変換でひらがなフィルタが意図せず救っていたこと。本記事では、入力中ハンドラが IME 経由ではなくコピペ専用の役割になっていたこと。動かしてみないと分からない、というのが、シリーズ全体で繰り返し効いてきた感覚でした。過去の受託案件で「半角カナで送られてきた値」を見たときの違和感は、いまでも覚えています。当時はサーバーで1行で済ませてしまいましたが、いま同じ案件をやるなら、クライアント側で先回りして変換する選択肢も提案できます。シリーズはこれで一区切りですが、日本語入力フォームの世界はもっと広いです。住所オートコンプリート、電話番号のハイフン自動挿入、生年月日のフォーマット統一など、続きは案件で実装するたびに、また検証メモとして書く予定です。
検証環境と、未確認の環境
この記事のコードと挙動の確認は、macOS Tahoe 26.4.1、Google Chrome 148、ATOK 35.0.3 で行いました。
未確認の環境は、Safari、Firefox、Edge、Windows + MS-IME、Google 日本語入力、iOS、Android です。本番フォームに導入するときは、想定するユーザー環境で動作確認をしてください。とくに Windows + MS-IME や Google 日本語入力では、本記事で観測した「IME 経由の input は isComposing=true でしか発火しない」挙動が同じとは限りません。古いブラウザや別の IME では、IME 確定後に isComposing=false の input が追加で発火するパターンもあるので、入力中ハンドラの挙動が今回と違う可能性があります。
参考にした公式ドキュメント
- MDN Web Docs: String.prototype.normalize() ― Unicode 正規化を実行する JavaScript の組み込みメソッド。NFKC/NFC/NFD/NFKD の各形式について解説。
- Unicode Technical Report #15: Unicode Normalization Forms ― NFKC を含む Unicode 正規化形式の仕様書。「互換等価」分解の対象文字について詳述。
- MDN Web Docs: HTMLInputElement.setSelectionRange() ― input 要素のカーソル位置・選択範囲を制御する API。
- PHP マニュアル: mb_convert_kana ― PHP のサーバー側で半角・全角変換を1行で行うための関数。
- MDN Web Docs: MutationObserver ― 動的に追加される DOM 要素の検知 API。条件付きフィールドや複数ステップフォームへの対応で使用。
関連記事
- 姓名フォームのフリガナ自動入力を composition イベントで自前実装した話 ― 本記事と同じシリーズ。
compositionendでの値の取り方を解説。 - 日本語入力の Enter でフォームが誤送信される問題を直した話|Safari・React・Vue 対応 ― 同じ IME まわりの実装で、Enter キーの誤送信を防いだ記録。
- Contact Form 7 で zipaddr-jp が動かなかった話|郵便番号→住所自動入力で踏んだ id 命名規則の罠 ― 同じ Contact Form 7 を使ったフォーム実装。郵便番号→住所自動入力の踏み抜きどころ。
- 「あ」→「雨」を自力で実装する|IME に頼らない日本語サジェストの作り方 ― シリーズ1本目。日本語サジェスト UI の基礎実装。
- 日本語サジェストの実装版|キーボード操作と blur 競合まで直して、ようやく使える検索 UI にした話 ― シリーズ2本目。blur まわりの挙動を実測で詰めた話。


コメント