
先週の夜、机に向かって、自分で作った WordPress テーマのソースコードを開きました。1年近く放置していたテーマです。バグというより、知人との雑談で「あれ、もう一度動かせないか」という話が出て、久しぶりに手を入れようと思ったのがきっかけでした。
VS Code でフォルダを開いて、ファイルツリーを眺めて、ファイル名から「ここから読めばよさそうだ」と当たりをつけて、1つ目のファイルを開きました。
開いて、5分。閉じました。
書いたはずなのに、何が書いてあるのか、分からなかったんです。
本記事の確認日:2026年5月26日 / 記事中で振り返る開発期間:2025年春〜秋。開発当時の環境:WordPress 6.8(当時の現行版)/ PHP 8.3.21 / Local by Flywheel + Xserver スタンダードプラン。使用していた AI コーディング補助:Claude Code、Cursor、ChatGPT(GPT-4 系)。テーマは仮に LMS と呼びます。
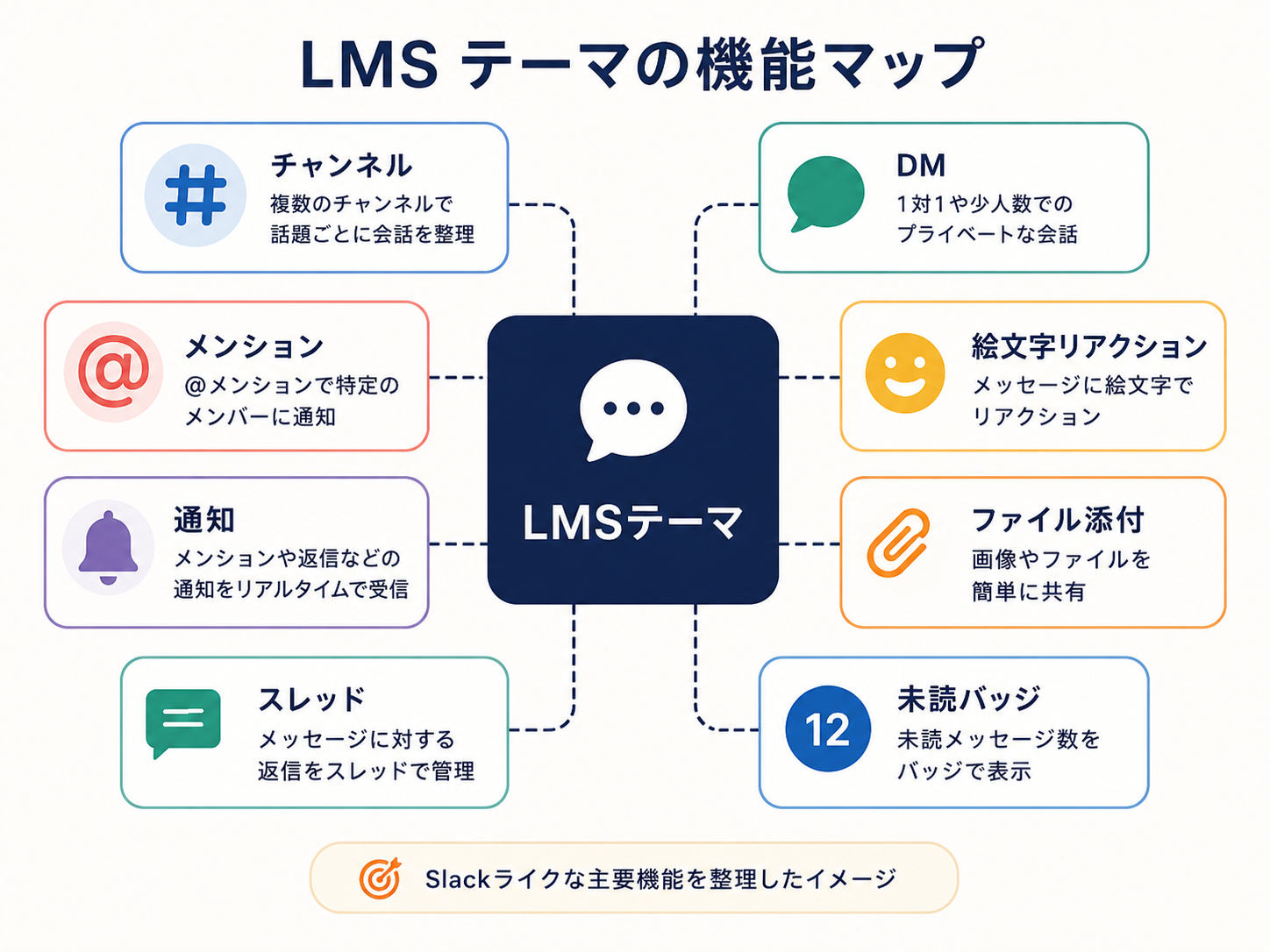
1年前、Slack ライクなテーマを8割AIで作っていた
2025年の春から秋にかけて、Slack ライクなコミュニケーションテーマを自分で作っていました。仮に LMS と呼びます。社内やコミュニティで使うことを想定していて、機能はかなり盛り込みました。チャンネル、DM、メンション、通知、絵文字リアクション、ファイル添付、スレッド、未読バッジ。Slack で日常的に使う機能は、ほぼ一通り実装したつもりです。
きっかけは単純で、Slack の有料プランが社外コミュニティで使うには重く感じていたことと、当時の自分が AI コーディングの勢いに乗っていたことが重なった結果でした。「これくらいなら作れるのでは」という感覚があって、深く考えずに着手しました。
最初の数週間で、チャンネル一覧とメッセージ投稿は動くようになりました。気持ちよかったのを覚えています。AI に頼めばコードが出てくる、貼り付けたら動く、また次へ。その繰り返しが楽しくて、機能を増やすことが目的になっていました。
完成後にクライアントへ評価で出してみたのですが、そのまま立ち消えになりました。よくある話です。フィードバックが返ってこないまま時間だけが経って、こちらから動く理由もなくなり、別案件で忙しくなって、LMS のことは頭の片隅に追いやられていきました。
そのうち WordPress 7.0 のリリース対応や、自作プラグインのメンテで忙しくなり、LMS のことを思い出すこともなくなりました。
それが先週、知人との雑談で「Slack 代替を自分で持ちたい」みたいな話が出て、「そういえば作ったやつがあった」と思い出して、ソースを開いたわけです。
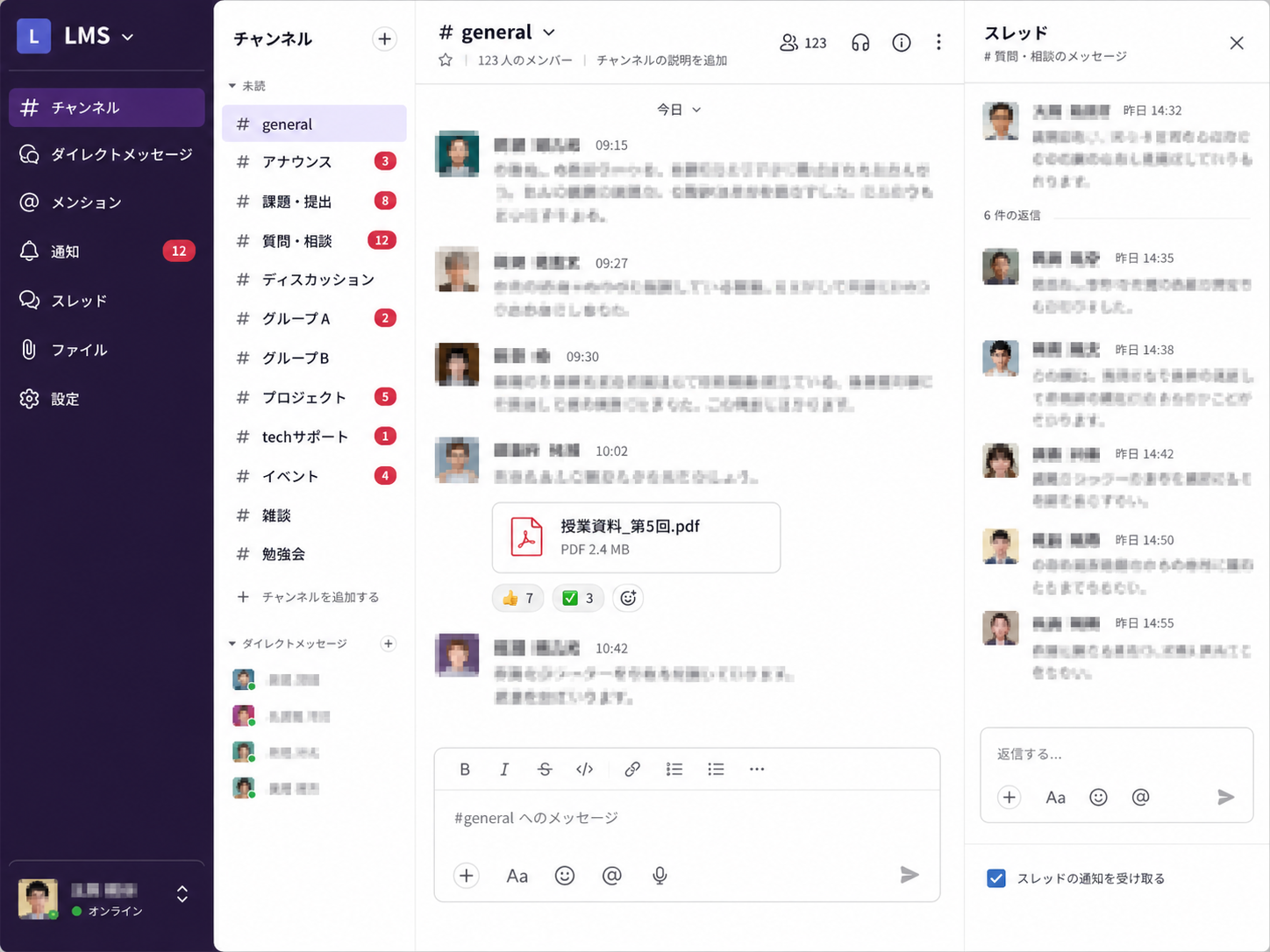
開いて5分、ソースが読めなくて閉じた
何が起きたか、できるだけ具体的に書きます。
ファイルツリーを眺めて、最初に開いたのが channel-controller.php のような名前の中心的なファイルでした。PHP のファイルだけで数十個、JavaScript と CSS を合わせるとさらに膨らみます。当時の自分はこの構成をどう決めたのか、思い出せませんでした。
開いたファイルの中身は、自分の理解を超えていました。関数名から処理の中身が想像できません。processMessage のような抽象的な名前の関数があちこちにあって、どれがチャンネルのメッセージを処理する関数で、どれが DM の関数なのか、開いて中を読むまで分かりません。
ためしに processMessage を grep で探すと、3つのファイルから見つかりました。引数は似ているのですが、中身の処理が微妙に違います。当時の自分は「ここはチャンネル用、ここは DM 用、ここはスレッド用」と区別したつもりだったのかもしれませんが、今読むと違いが分かりません。同じ名前の関数を別々のファイルに作って、呼び出し側が間違えたら一発で動かなくなる構造です。
ヘルパー関数も妙に細かく分かれていました。getUserNameById getUserNameFromCache getUserDisplayName formatUserName。すべて自分が書いたはずですが、どれがどれを呼んでいて、どこで使われているのか、追いかけるだけで時間が溶けます。
コメントは英語と日本語が混ざっています。// Handle the case where user is not authenticated のすぐ下に「未読バッジを更新」と日本語コメントが続いていたりします。当時は気にしなかった、というより、AI が生成したコメントをそのまま受け入れていました。コメントを書き直す手間と、機能を1つ追加する手間を天秤にかけて、後者を取り続けた結果です。
そして、明らかに使われていないデッドコードが、あちこちに残っています。// TODO: remove after refactoring というコメント付きの関数が、コメントだけ残ったままどこからも呼ばれていない状態で生き残っています。リファクタリングはついぞ行われませんでした。
ファイル単位で見ても、空に近いものが混ざっています。「分離する予定だったけど結局使わなかった」ファイルが、削除されないまま残っています。中身は半分くらい書かれていて、もう半分が // TODO のまま。
コミットログを追えば誰が書いたかは特定できますが、ほぼ全部、自分です。
5分眺めて、閉じました。
当時、8割をAIに書かせていたやり方
当時のコードは、感覚で言えば 8 割を AI に書いてもらっていました。Claude Code、Cursor、ChatGPT。複数の AI を使い分けながら、Slack の機能を1つずつ実装していきました。
1日の作業フローはだいたい決まっていました。朝、コーヒーを淹れて Cursor を立ち上げて、「今日はチャンネルの未読カウントを実装する」と決めます。AI に「未読カウントを Slack っぽく実装するにはどうしたらいいか」と聞いて、返ってきた設計案をざっと読んで、「これで進めて」と返事をします。AI がコードを書きます。コピーして貼り付けます。動かなければエラーメッセージを貼り直して、修正案をもらって、動いたら次へ。
AI ごとの使い分けも、なんとなくありました。複雑な構造を考えるときは Claude Code、ファイルの中で部分的に書き換えるときは Cursor のインライン補完、調べ物や設計の壁打ちは ChatGPT。はっきりした基準があったわけではなくて、その日の気分や、開いていたタブで決まることが多かったです。
Long Polling まわりも AI 補助で書きました。WebSocket が Xserver で使えなかったので、Long Polling か SSE で代替する必要があったんですが、その実装の試行錯誤は Xserver でリアルタイムチャットを Long Polling で作った話に少し書いています。あの記事の Long Polling のサンプルコードは整理して載せていますが、LMS の中で実際に動いているコードは、もっと複雑で、もっと汚いです。記事に載せるために整形した状態と、本物のコードはまったく別物でした。
問題は、書くスピードに、自分の理解が追いつかないまま走ってしまったことでした。
動けば、次。動けば、次。
仕様書は書いていません。設計図もありません。ファイル構造はその場の思いつきで、関数の責務もあいまいなまま、機能だけが増えていきました。テストコードはゼロ。「とりあえず動くものを早く」というモードで、半年ほど突っ走りました。
新しい機能を実装するときの判断も、雑になっていきました。「この処理、前にも書いた気がする」と思っても、過去のファイルを探すより AI に書かせ直したほうが速いと判断します。結果、似た処理が3か所に存在することになります。これが後の重複定義の地獄を生みました。
当時、AI を使うこと自体は間違っていないと、今でも思っています。あのスピードがなければ、LMS は完成にすら届きませんでした。問題は、AI に書かせている間、自分が「コードのレビュアー」ではなく「コピー&ペーストの仲介役」になっていたことです。コードの良し悪しを判断する役割を、自分が放棄していました。
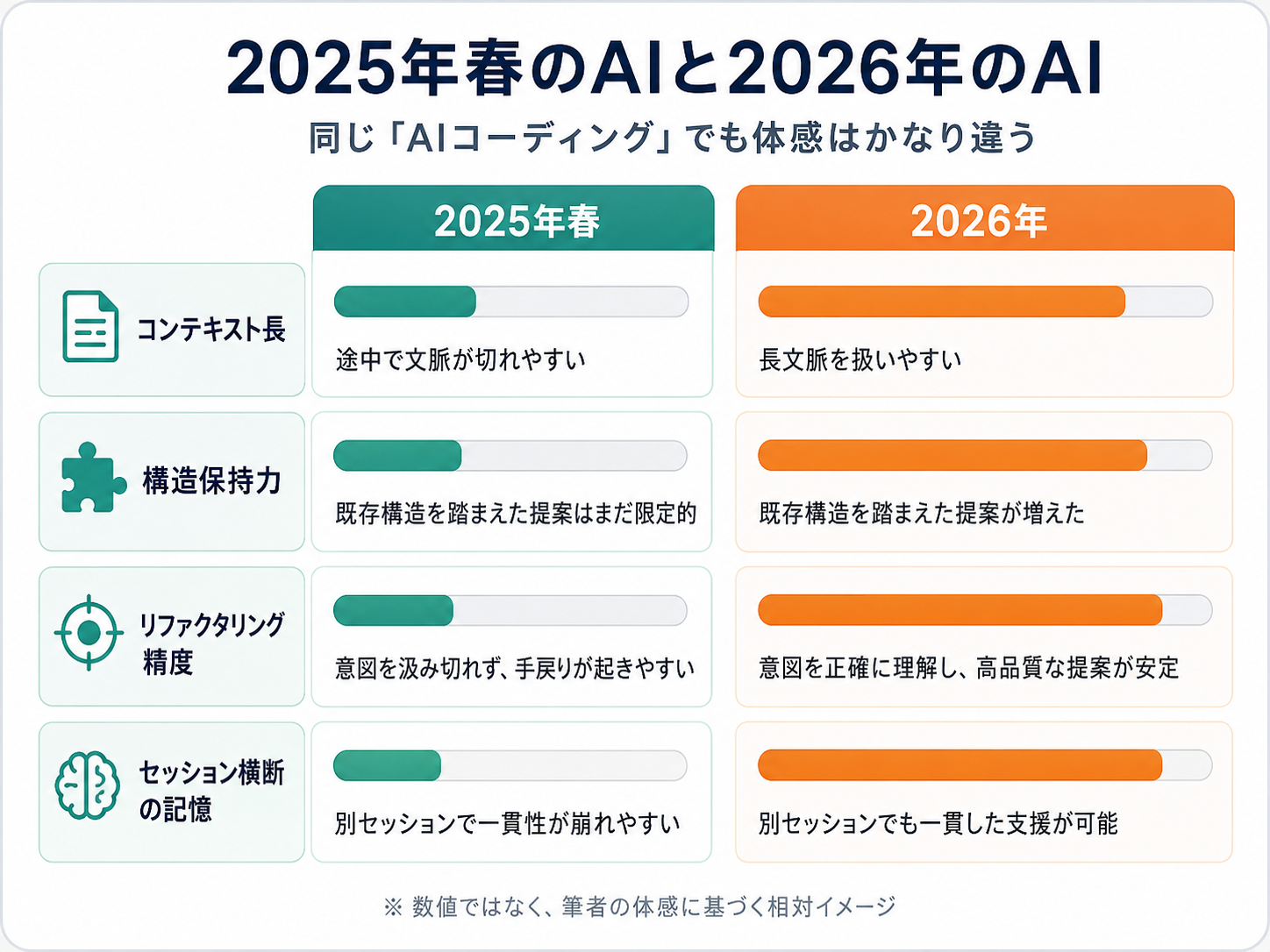
2025年春のAIと、2026年のAIは別物
もう一つ、正直に書いておきます。
2025年春〜秋頃の AI コーディングは、今ほど成熟していませんでした。当時使っていたのは Claude 3.5 Sonnet、GPT-4o、それから Cursor の組み込み AI。どれも当時としては強力でしたが、今のモデルと比べると一段下です。
生成されるコードの品質も、構造を保つ能力も、今と比べると違います。同じ処理を別の言葉で再度頼むと、まったく違うコードを書いてくる。前回の設計を覚えていてくれない。リファクタリングを頼むと、関係ないところまで書き換えてしまう。「このファイルの関数 A を改善して」とお願いしたら、関数 A と一緒に関数 B と関数 C も別物になって返ってきて、差分を見ながら「あれ、これ何が変わったんだっけ」と確認に時間を取られる、みたいなことがよくありました。
コンテキスト窓も今より短くて、長いファイルを丸ごと貼り付けると AI 側が「途中までしか覚えていない状態」になっていました。当時の自分はそれに気づかず、「ファイル全体を見せたつもり」で AI と会話していたので、AI の返答がしばしばファイル前半だけを前提にしていました。これに気づかないまま「動くから OK」で先に進んだ箇所が、たぶん今のデッドコードの一部です。
そういう AI と長期プロジェクトを進めると、コードは確実にスパゲッティ化します。当時の自分は、AI のクセに自分の書き方を合わせず、機能追加のたびに新しい AI セッションを開いて、新しいファイルを増やしていきました。「前のセッションの続きから」ではなく「新しいセッションでゼロから」を繰り返すと、設計の一貫性は保てません。
結果が、今のソースです。
今の Claude Code や Cursor は、長いコンテキストを保ち、ファイル横断で構造を考えながら書いてくれます。同じ機能を頼むと、まずプロジェクト構造を読みに行って、既存の関数があれば使い回し、なければ既存の命名規則に合わせて新しい関数を作ってくれます。1年前の自分が苦労していた「設計の一貫性」の部分を、AI 側がかなり支えてくれるようになりました。
でも 2025年春の AI と一緒に書いたコードは、当時の AI の限界をそのまま引きずっています。今の AI に「これをきれいにして」と頼むこともできるはずですが、AI が「きれいにする」過程で本来の挙動が失われるリスクもあるので、まだ踏み切れていません。
AI のせいにするつもりはありません。AI のクセを理解せずに走ったのは自分です。ただ、「AI コーディングは速い」という一面だけ見ていた当時の自分には、もう少し慎重さがあってよかったと思っています。
今どう向き合っているか
正直に書きます。
向き合えていません。
ソースが多すぎて、どこから読み解こうか考えている段階です。少なくとも、いきなり修正に入れる状態ではありません。
今やろうとしていることを書き出してみます。
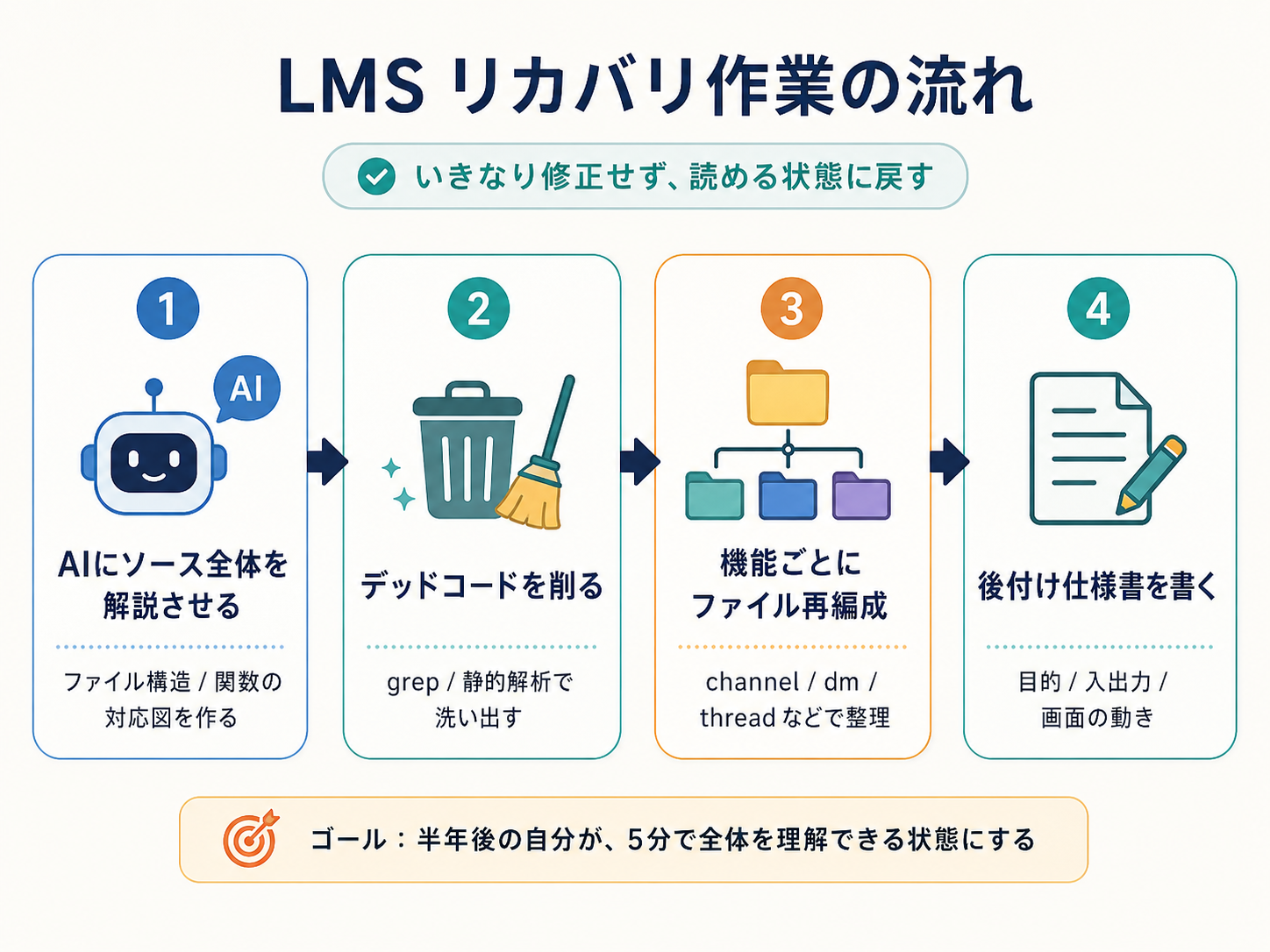
まず、Claude Code に LMS のソース全体を読ませて、ファイル構造と関数の対応図を作ってもらうつもりです。「このファイルは何をしているか」「この関数はどこから呼ばれているか」を、AI に説明させて、自分が読める形に直す作業です。プロンプトとしては「このプロジェクトの主要なファイルを5つ挙げて、それぞれの責務を50字以内で書いてください」みたいなところから始めます。AI に書かせたコードを、AI に解説させる。皮肉な構図ですが、今のところこれが一番現実的に思えます。
次に、デッドコードを洗い出して削ります。これは grep でも追える話で、参照されていない関数や、コメントアウトされたまま残っているブロックを物理的に消します。PHP なら静的解析ツール(PHPStan や Psalm)で「Dead code」「Unused method」を検出させると速いです。JavaScript なら ESLint のルールで似たことができます。当時はこういうツールを通していなかったので、まずは通すところから始めます。
それから、機能ごとにファイルを再編成します。今は「チャンネル」「DM」「スレッド」が同じファイルに混ざっていたり、逆に同じ機能の処理が複数ファイルに分かれていたりします。1機能=1ファイル(または1ディレクトリ)に整理し直す予定です。Slack の機能分類を参考に、channel/ dm/ thread/ notification/ attachment/ のような大枠を作って、その中に必要なファイルだけを置きます。
ここまで終わって、ようやく仕様書を書く準備ができると思っています。コードを読みながら、当時の自分が「何をしようとしていたか」を推測して、後付けで仕様書を作る。仕様書のテンプレートも、なるべく軽いものを使うつもりです。機能名、目的、入出力、画面の動き、データの流れ。各項目を箇条書きで埋めるだけのフォーマットにしておけば、書く側の負担も読む側の負担も小さくなります。
これが一番気が重い作業です。書いている最中に「この機能、何のために作ったんだっけ」という瞬間が何度も来ると思います。
完了予定は、立てていません。本業の合間に少しずつ進めるつもりです。半年かかるか、もしかしたら作り直しの判断をするかもしれません。作り直しの方が早いケースは、現実にはよくあります。
次に作るときに自分に課したいルール
LMS のリカバリが終わってからの話、というより、今ここで決めておかないと、同じことを繰り返します。
仕様書は、機能ごとに小さくてもいいから書きます。「このチャンネルの機能は何ができるか」「この通知はいつ飛ぶか」を、自然言語で残します。AI にコードを書かせる前に、仕様書を書く。仕様書がないままコードを書き始めない。LMS でいえば、channel.md には「チャンネルは複数のメンバーが投稿できる場所。投稿は時系列順。最新メッセージは下端。未読数はメンバーごとに保持」みたいな短い説明を残しておけば、半年後の自分でも「ああ、そういう設計だったな」と思い出せるはずです。
ファイル構造は、最初に決めます。途中で「ここに置こう」と思いつきで増やしません。Slack ライクなものなら、最初に channel/ dm/ thread/ notification/ のような大枠を切ってから、各ディレクトリの中で機能を実装します。新しい機能を作るときは「既存のディレクトリのどれに属するか」を考えて、当てはまらない場合だけ新しいディレクトリを作る、というルールにします。「とりあえずルートに置こう」を禁止するだけで、構造は格段に保てます。
関数名は、AI 任せにしません。AI が processData と書いてきたら、postMessageToChannel のように、自分の言葉で書き直します。命名のルールも事前に決めておくと楽です。動詞 + 目的語、もしくは目的語 + 状態。getUserById markMessageAsRead notifyMentionedUser。AI が違うパターンの命名を提案してきたら、それを自分のルールに合わせ直す。手間は5秒です。
コメントも同じです。AI の生成した英語コメントを、自分の言葉の日本語に直す。1関数につき1行でいいから、自分で書いたコメントを残します。書くのは「この関数が何をするか」ではなく「なぜこの処理が必要か」のほう。「なぜ」だけは AI には書けません。
テストコードは、軽くてもいいから書きます。実装と同じタイミングで書く。後から書こうと思うと、LMS のように一生書けない状態に追い込まれます。粒度はユニットテストで十分です。「この関数に入力 X を渡すと出力 Y が返る」というレベルでいい。E2E テストや統合テストは、プロジェクトが落ち着いてからで構いません。
長期で触るプロジェクトでは、AI セッションを毎回新しくしない。前のセッションの履歴を読ませる、コンテキストを引き継ぐ。今の Claude Code はこのあたりが格段に良くなっていますが、それでも自分側で「過去の設計を覚えさせる」意識は要ります。プロジェクトのルートに CLAUDE.md のようなメモを置いて、設計方針、命名規則、ファイル構造を書いておくと、AI 側もそれを参考にしてくれます。
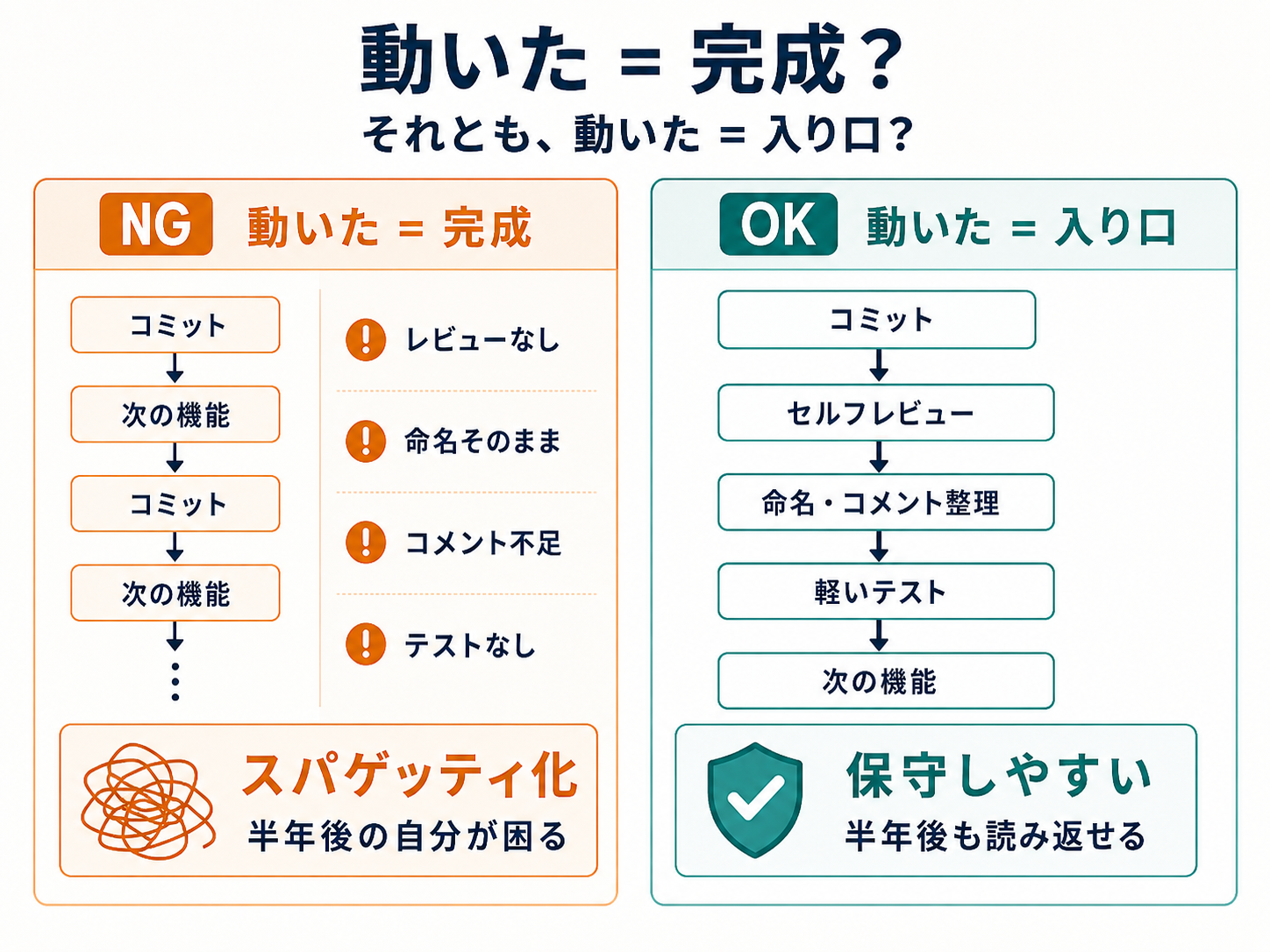
そして一番大事なことを最後に。動いた瞬間を完成にしません。動いた瞬間は、ようやく入り口に立った瞬間です。コミットする前に、自分で1分だけコードを読み返す。命名がおかしくないか、コメントが残せているか、デッドコードが混ざっていないか。1分のセルフレビューが、半年後の自分を救います。
次の自分に渡すメモ
ここまで書いてきたことを、もう一度短く、自分のために書き留めておきます。
AI と書いたコードも、自分のコードです。動いた瞬間が完成じゃなくて、半年後の自分が読めて初めて完成。
仕様書を書かないままコードを書き始めない。
関数名とコメントは、AI 任せにしないで自分の言葉で書き直す。
ファイル構造は最初に決めて、思いつきで増やさない。
テストコードは軽くてもいいから、実装と同じタイミングで書く。
動いた瞬間を完成にしない。
AI は同僚みたいなものだと思ってます。便利だし、いてくれないと困る。でも、書いたコードの責任は自分にあります。当たり前のことを、LMS のソースコードを開いて閉じた5分間で、ようやく思い出しました。
LMS をどう復活させるか、決まったらまた記事にします。たぶん時間がかかります。書き直しの判断をしたら、そのときはそのときで、なぜ書き直しを選んだかを記録に残すつもりです。失敗から学ぶには、失敗を残しておくしかありません。
本記事の確認日は2026年5月26日です。記事中で言及した Long Polling 実装の試行錯誤については、Xserver でリアルタイムチャットを Long Polling で作った話を合わせてご覧ください。AI コーディングの方針や、WordPress プラグイン開発の実体験は、当サイトの Web Development カテゴリにまとめています。
コメント