
Googleの検索窓に「あ」と打つと、「雨」「赤」「青」といった漢字の候補がすっと表示される。あれを自分のサイトでもやりたいと思ったことはありませんか?
私はブログの検索機能を改善しようとしたとき、最初に「IMEの変換候補を取得すればいいのでは」と考えました。でもそのアプローチは不可能でした。ブラウザからIMEの内部にはアクセスできない——これはバグではなくセキュリティ上の意図的な設計です。
では実際にどうするかというと、「漢字と読みの辞書」を自前で持ち、ひらがなで前方一致検索をかけます。IMEの力を借りるのではなく、IMEを迂回して自力で候補を出すわけです。
この記事では、この「読み検索」方式の日本語サジェストを、HTMLとJavaScriptだけでゼロから実装します。IMEの合成イベント対応、debounce、プレフィックス検索のロジックまで一通りカバーするので、この記事だけで動くものが作れます。
完成イメージはこちらです。入力欄に「あ」と打つと、読みが「あ」で始まる漢字候補がドロップダウンで表示されます。
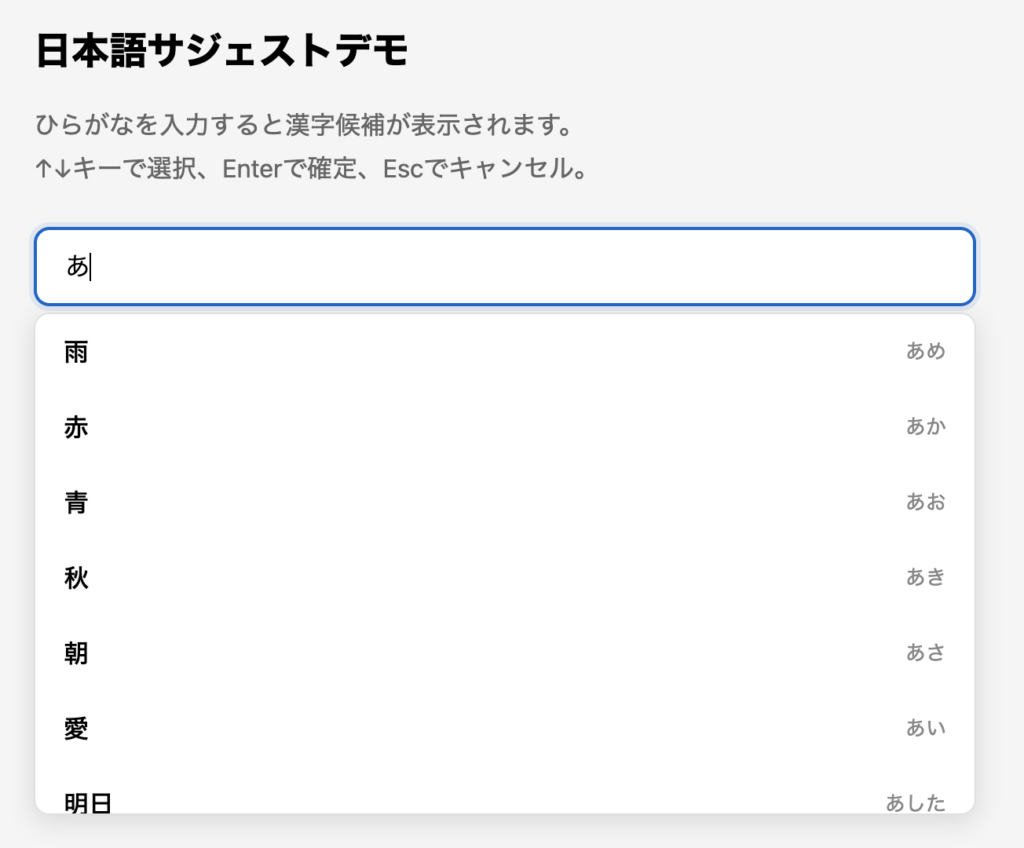
▲ 完成したサジェスト機能のデモ画面(「あ」で候補が表示されている状態)
この記事の結論
日本語サジェストはIMEの変換候補ではなく、自前の辞書データに対する「読みの前方一致検索」で実現します。ブラウザからIMEの内部にはアクセスできません。実装の核心はcompositionstart/compositionendイベントで合成中を判定し確定時だけ検索を実行すること、debounceで連続確定の暴発を防ぐことの2つです。
応用編(外部API連携、サーバーサイド実装、パフォーマンス最適化)は後編で扱います。

この記事は2部構成です
Part 1(この記事):日本語サジェストの基本的な仕組みとIMEに頼らない実装方法
Part 2:日本語サジェスト完全版|キーボード操作・blur落とし穴・API連携
なぜIMEの変換候補は取得できないのか
IMEはOSレベルで動作するソフトウェアで、ブラウザのJavaScriptからは内部状態にアクセスできません。セキュリティとプライバシーを守るための意図的な設計です。
最初にこの疑問をクリアにしておきます。「IMEが持ってる候補をJavaScriptで読めばいいじゃん」——これは多くの人が最初に思いつくアプローチですが、技術的に不可能です。
IME(Input Method Editor)はOSレベルで動作するソフトウェアで、ブラウザのJavaScriptからは内部状態にアクセスできません。その理由はセキュリティとプライバシーです。
もしWebサイトがIMEの変換候補を取得できたら何が起きるか。ユーザーが入力しようとしている文字列を確定前に盗み見できてしまいます。しかもIMEには学習機能があるので、過去に変換した単語——家族の名前、住所、勤務先なども候補に含まれています。これらがWebサイト側に漏れるのは明らかにまずい。
ブラウザが提供してくれるのは、IMEが「合成中かどうか」と「合成が終わったかどうか」の2つの情報だけです。変換候補の中身には触れさせてもらえません。
正しいアプローチ:「読みによる前方一致検索」
IMEに頼らず、自前で「漢字と読み」のペアを持った辞書データを用意し、ひらがなで前方一致検索をかける。これが正解です。
考え方をIMEの「変換」から「検索」に切り替えるのがポイントです。
|
1 2 3 4 5 6 7 8 |
辞書データの例: { text: "雨", reading: "あめ" } { text: "赤", reading: "あか" } { text: "青", reading: "あお" } { text: "秋", reading: "あき" } 入力「あ」→ 読みが「あ」で始まるもの全部ヒット → 雨, 赤, 青, 秋 入力「あめ」→ 読みが「あめ」で始まるものだけヒット → 雨 |
日本語は単語の先頭から順に入力するので、前方一致検索と相性がいい。入力が進むにつれて候補が絞り込まれていく——Googleの検索サジェストと同じ挙動です。
実装に必要なのは3つ。辞書データ、検索ロジック、表示UI。順番に作っていきます。
IMEの合成イベントを理解する——ここが日本語サジェストの核心
日本語入力にはIMEの「合成(composition)」があり、inputイベントだけ監視するとサジェストが暴発します。compositionstart/compositionendイベントで合成中を判定し、確定時だけ検索を実行するのが正解です。
英語のサジェストならinputイベントを監視するだけで済みますが、日本語はそうはいきません。日本語入力にはIMEによる「合成(composition)」というステップがあり、これを正しく扱わないとサジェストが暴発します。
何が起きるのか:inputイベントの暴発問題
「あめ」と入力する場合を考えてみてください。キーボードで「a」「m」「e」と打つと、inputイベントは3回発火します。
|
1 2 3 4 |
1. 「a」を押す → inputイベント発火(入力欄:「あ」) ← まだ未確定 2. 「m」を押す → inputイベント発火(入力欄:「あm」) ← まだ未確定 3. 「e」を押す → inputイベント発火(入力欄:「あめ」) ← まだ未確定 4. Enterで確定 → inputイベント発火(入力欄:「あめ」) ← 確定 |
もしinputイベントが発火するたびに検索を実行したら、「あ」の時点で候補が出て、「あm」で候補が消えて、「あめ」でまた出て……と表示がガタガタになります。
解決策:compositionイベントで合成中を判定する
ブラウザは、IMEの合成状態を3つのイベントで通知してくれます。
compositionstart——IMEによる合成が始まったとき。「今からIMEで入力するよ」という合図。
compositionupdate——合成中のテキストが更新されるたび。ローマ字→ひらがな変換のたびに発火。
compositionend——合成が終了(確定)したとき。「入力が確定したよ」という合図。
サジェスト検索を実行するベストなタイミングはcompositionendです。確定したときだけ検索を走らせれば、暴発問題は解決します。
実装:フラグ変数で合成中を追跡する
inputイベントのisComposingプロパティで判定できますが、古いSafariやiOSでは正しく動かないケースがあります。自前のフラグ変数を併用するのが確実です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
const input = document.getElementById('searchInput'); let isComposing = false; // 合成開始 → フラグON input.addEventListener('compositionstart', () => { isComposing = true; }); // 合成終了 → フラグOFF → 検索実行 input.addEventListener('compositionend', () => { isComposing = false; performSearch(input.value); // ← ここで検索 }); // inputイベント → 合成中ならスキップ input.addEventListener('input', (e) => { if (e.isComposing || isComposing) { return; // 合成中は何もしない } performSearch(e.target.value); // 英字入力などIME不使用時 }); |
e.isComposing || isComposingで二重チェックしているのは、ブラウザ間の差異を吸収するためです。Chrome、Firefox、Safari、Edgeのどれでも動きます。
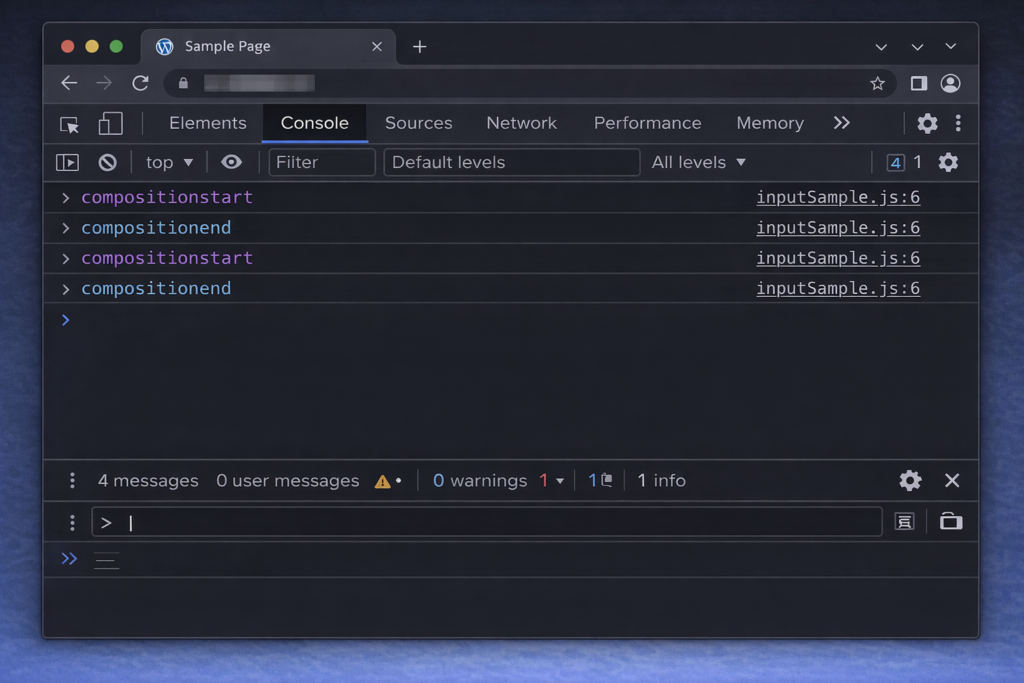
debounce——連続入力による無駄な検索を防ぐ
debounceは「最後の入力から一定時間(150ms程度)経つまで検索を待つ」仕組みです。連続確定による無駄なチラつきを防ぎ、ローカル検索ならほぼ即時に見えるレスポンスが実現できます。
IMEの合成中は検索をスキップできるようになりました。次の問題は「連続確定」です。
「天気予報」と入力するとき、「てんき」確定→「よほう」確定と2回の確定が発生します。確定のたびに検索を実行すると、「てんき」の検索結果が一瞬表示されてすぐ消える。ユーザーにとっては無駄なチラつきです。
debounceは、「最後の入力から一定時間(150ms程度)経つまで検索を待つ」仕組みです。入力が続いている間はタイマーをリセットし続け、入力が落ち着いたら1回だけ検索を実行します。


debounceありの場合、入力があるたびにタイマーがリセットされ、最後の入力から150ms後に1回だけ検索が走っています。
debounce関数の実装
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
function debounce(func, delay) { let timeoutId = null; return function(...args) { // 前回のタイマーがあればキャンセル if (timeoutId !== null) { clearTimeout(timeoutId); } // 新しいタイマーを設定 timeoutId = setTimeout(() => { func.apply(this, args); }, delay); }; } // 使い方 const debouncedSearch = debounce(performSearch, 150); |
setTimeoutで遅延実行を仕掛けつつ、次の呼び出しが来たらclearTimeoutで前のタイマーをキャンセルする。シンプルですが効果は絶大です。
遅延時間は100〜300msが一般的です。150msはローカル検索(辞書データがブラウザ内にある場合)にちょうどいいバランスで、体感的にはほぼ即時に見えます。
プレフィックス検索のロジック
JavaScriptのfilterとstartsWithを組み合わせ、読みとテキスト両方で前方一致検索をかけます。完全一致を最優先にソートし、候補は最大10件に制限するのがポイントです。
いよいよ検索ロジックの実装です。JavaScriptのfilterとstartsWithを組み合わせます。
基本の検索関数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
function searchByReading(query) { const normalizedQuery = query.toLowerCase().trim(); if (!normalizedQuery) { return []; } // 読み OR テキスト自体で前方一致検索 let results = dictionary.filter(item => { return item.reading.startsWith(normalizedQuery) || item.text.toLowerCase().startsWith(normalizedQuery); }); // ソート:完全一致を最優先、次に読みが短いもの順 results.sort((a, b) => { const aExact = a.reading === normalizedQuery || a.text.toLowerCase() === normalizedQuery; const bExact = b.reading === normalizedQuery || b.text.toLowerCase() === normalizedQuery; if (aExact && !bExact) return -1; if (!aExact && bExact) return 1; return a.reading.length - b.reading.length; }); return results.slice(0, 10); } |
読みだけでなくテキスト自体も検索対象にしているのは、「アメリカ」を「あめりか」でも「アメリカ」でもヒットさせるためです。
ソートは完全一致を最優先にし、それ以外は読みが短いもの(より具体的な単語)を上に表示します。slice(0, 10)で候補を最大10件に制限——多すぎると選びづらくなるからです。
セキュリティ:HTMLエスケープを忘れない
候補をHTMLに挿入する際、textContent→innerHTMLでエスケープ処理を入れないとXSS脆弱性になります。辞書データが自前でも、将来の拡張を見据えて最初から入れておくべきです。
候補をHTMLに挿入する際、エスケープ処理を忘れるとXSS(クロスサイトスクリプティング)の脆弱性になります。辞書データが自前であっても、将来的にユーザー入力やAPI経由のデータを候補に含める可能性があるなら、最初からエスケープしておくべきです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
function escapeHtml(text) { const div = document.createElement('div'); div.textContent = text; return div.innerHTML; } // 候補をHTMLに挿入するとき li.innerHTML = ` ${escapeHtml(item.text)} ${escapeHtml(item.reading)} `; |
textContentに代入→innerHTMLで取り出すと、<や&が自動的にエスケープされます。地味ですが、本番運用では必須の処理です。
ここまでの全パーツを統合する
IME合成判定、debounce、プレフィックス検索、HTMLエスケープの4つのパーツを統合したコードを以下に示します。日本語でも英語でも正しく動作します。
IME合成判定、debounce、プレフィックス検索、HTMLエスケープ——ここまでのパーツを一つにまとめます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
// === 辞書データ === const dictionary = [ { text: '雨', reading: 'あめ' }, { text: '赤', reading: 'あか' }, { text: '青', reading: 'あお' }, { text: '秋', reading: 'あき' }, { text: '朝', reading: 'あさ' }, { text: 'アメリカ', reading: 'あめりか' }, { text: '天気', reading: 'てんき' }, { text: '天気予報', reading: 'てんきよほう' }, // ... サイトに合わせて追加 ]; // === ユーティリティ === function debounce(func, delay) { let timeoutId = null; return function(...args) { if (timeoutId !== null) clearTimeout(timeoutId); timeoutId = setTimeout(() => func.apply(this, args), delay); }; } function escapeHtml(text) { const div = document.createElement('div'); div.textContent = text; return div.innerHTML; } // === 検索ロジック === function searchByReading(query) { const q = query.toLowerCase().trim(); if (!q) return []; let results = dictionary.filter(item => item.reading.startsWith(q) || item.text.toLowerCase().startsWith(q) ); results.sort((a, b) => { const aExact = a.reading === q || a.text.toLowerCase() === q; const bExact = b.reading === q || b.text.toLowerCase() === q; if (aExact && !bExact) return -1; if (!aExact && bExact) return 1; return a.reading.length - b.reading.length; }); return results.slice(0, 10); } // === メイン処理 === const input = document.getElementById('searchInput'); let isComposing = false; input.addEventListener('compositionstart', () => { isComposing = true; }); input.addEventListener('compositionend', () => { isComposing = false; updateSuggestions(input.value); }); function updateSuggestions(query) { const results = searchByReading(query.trim()); console.log('検索結果:', results); // → 次のステップでUI表示を実装 } const debouncedUpdate = debounce(updateSuggestions, 150); input.addEventListener('input', (e) => { if (e.isComposing || isComposing) return; debouncedUpdate(e.target.value); }); |
動作の流れを確認
IMEで「あめ」と入力→確定した場合:
|
1 2 3 4 5 |
1. 「a」を押す → compositionstart → isComposing = true 2. inputイベント → isComposingがtrueなのでスキップ 3. 「m」「e」を押す → 同様にスキップ 4. Enterで確定 → compositionend → isComposing = false → updateSuggestions('あめ') 5. 検索結果: [{ text: '雨', reading: 'あめ' }, { text: 'アメリカ', reading: 'あめりか' }] |
IME不使用で「test」と入力した場合:
|
1 2 3 |
1. compositionstartは発火しない → isComposingはfalse 2. inputイベント → debouncedUpdateが呼ばれる 3. 150ms後にupdateSuggestionsが実行される |
日本語でも英語でも正しく動くことが確認できました。
次のステップ:UIの構築と完全版コード
ここまでで日本語サジェストの「頭脳」部分は完成しています。後編では候補表示UI、キーボード操作、フォーカス制御を実装し、コピペで動く完全なサンプルコードに仕上げます。
ここまでで、日本語サジェストの「頭脳」部分(IME対応 + 検索ロジック)は完成しています。
後編では、この検索ロジックに「体」を与えます。HTMLとCSSで候補表示UIを構築し、キーボード操作(↑↓キー、Enter、Escape)、マウスクリック、フォーカス制御まで実装して、コピペで動く完全なサンプルコードを仕上げます。さらに、外部API連携やサーバーサイド実装など、本番運用向けの応用テクニックもカバーします。
macOSの日本語入力には、最初の1文字だけ英字になる独特の問題もあります。IMEとイベント処理の関係を掘り下げた記事はこちらです。

まとめ
「あ→雨」はIMEの変換ではなく、読みによる前方一致検索で実現する。IMEの変換候補にはブラウザからアクセスできないので、辞書データを自前で持ち、startsWithで検索をかけるのが正しいアプローチです。
日本語特有の課題はIMEとの共存です。compositionstart/compositionendイベントで合成中を判定し、合成中は検索をスキップする。加えてdebounceで連続確定による無駄な検索を防ぐ。この2つを組み合わせれば、日本語でもストレスのないサジェスト体験が実現できます。


コメント